Logstash
https://github.com/elastic/logstash
Logstash is an open source data collection engine with real-time pipelining capabilities。 Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
Logstash作为Elastic Stack的重要组成部分,在Elasticsearch数据采集和处理过程中扮演着重要的角色。
概念
Logstash Pipeline:
Data Source -> INPUTS | FILTERS | OUTPUTS -> Elasticsearch输入(inpust): 【必选】 负责产生事件(Inputs generate events),常用:File、syslog、redis、beats(如:Filebeats)。 Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。 Logstash 能够以连续的流式传输方式,轻松地从日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
过滤器(filters): 【可选】 负责数据处理与转换(filters modify them),常用:grok、mutate、drop、clone、geoip。 Logstash 过滤器能实时解析和转换数据,数据从源传输到存储库的过程中。 Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
- 利用 Grok 从非结构化数据中派生出结构
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段
- 简化整体处理,不受数据源、格式或架构的影响
输出(outpus): 【必须】 负责数据输出(outputs ship them elsewhere),常用:elasticsearch、file、graphite、statsd。 Logstash 提供众多输出选择,可以将数据发送到指定的地方,并且能够灵活地解锁众多下游用例。
编码插件(Codeos): 【可选】 在Logstash的数据流(input|decode|filter|encode|output)中描述decode/encode的处理,常用:json、multiline、rubydebug
目录
目录结构: https://www.elastic.co/guide/en/logstash/7.1/dir-layout.html
.
├── logs/ # 日志文件
├── bin/ # 二进制脚本,包括用于启动Logstash的logstash和用于安装插件的logstash-plugin
├── config/ # Configuration files,including logstash.yml and jvm.options
│ ├── logstash.yml # 用于控制logstash的执行过程。参考:https://www.elastic.co/docs/reference/logstash/logstash-settings-file
│ ├── pipelines.yml # 如果有多个pipeline时使用该配置来配置多pipeline执行。参考:https://www.elastic.co/docs/reference/logstash/multiple-pipelines
│ ├── startup.options # 仅适用于Lniux系统,用于设置系统启动项目!
│ ├── log4j2.properties # 日志。参考:https://www.elastic.co/docs/reference/logstash/logging
│ └── jvm.options
├── data/
├── jdk/ # 【兼容性】Java程序运行环境
├── lib/
├── logstash-core/
├── logstash-core-plugin-api/
├── vendor/
├── modules/
├── tools/
├── x-pack/
├── CONTRIBUTORS
├── Gemfile
├── Gemfile.jruby-2.3.lock
├── JDK_VERSION
├── LICENSE
└── NOTICE.TXT安装
本体安装
安装方式一:压缩包安装
下载:
解压以后可以对logstash进行简单的测试。
bin/logstash -e 'input { stdin {} } output { stdout {} }'
kkk
{
"event" => { # Logstash 将数据流中等每一条数据称之为一个事件(event)。
"original" => "kkk"
},
# type 标记事件的唯一类型
# tags 标记事件的某方面属性。可以有多个标签,可以通过过滤器中 add_tag/remove_tag/add_field/remove_field 匹配成功时生效
"@timestamp" => 2025-11-23T04:20:54.481028474Z, # 标记事件的发生时间
"message" => "kkk",
"host" => { # 标记事件发生的设备
"hostname" => "demo-se-elk"
},
"@version" => "1"
}安装方式二:RPM包安装
todo
安装方式三:Docker运行
todo
插件安装
虽然logstash默认安装了大部分的插件,但是有些插件没有默认安装,如logstash-output-syslog、logstash-output-jdbc
相关信息
插件运行需要ruby运行环境
$ yum install -y gem
$ gem -v
2.0.14.1
$ gem update --system
$ gem -v
3.1.2已安装的插件
$ bin/logstash --version
Using bundled JDK: /home/vagrant/wk/demo-01-logstash/logstash-9.2.1/jdk
logstash 9.2.1
$ bin/logstash-plugin list
Using bundled JDK: /home/vagrant/wk/demo-01-logstash/logstash-9.2.1/jdk
logstash-codec-avro
logstash-codec-cef
logstash-codec-collectd
logstash-codec-dots
logstash-codec-edn
logstash-codec-edn_lines
logstash-codec-es_bulk
logstash-codec-fluent
logstash-codec-graphite
logstash-codec-json
logstash-codec-json_lines
logstash-codec-line
logstash-codec-msgpack
logstash-codec-multiline
logstash-codec-netflow
logstash-codec-plain
logstash-codec-rubydebug
logstash-filter-aggregate
logstash-filter-anonymize
logstash-filter-cidr
logstash-filter-clone
logstash-filter-csv
logstash-filter-date
logstash-filter-de_dot
logstash-filter-dissect
logstash-filter-dns
logstash-filter-drop
logstash-filter-elastic_integration
logstash-filter-elasticsearch
logstash-filter-fingerprint
logstash-filter-geoip
logstash-filter-grok
logstash-filter-http
logstash-filter-json
logstash-filter-kv
logstash-filter-memcached
logstash-filter-metrics
logstash-filter-mutate
logstash-filter-prune
logstash-filter-ruby
logstash-filter-sleep
logstash-filter-split
logstash-filter-syslog_pri
logstash-filter-throttle
logstash-filter-translate
logstash-filter-truncate
logstash-filter-urldecode
logstash-filter-useragent
logstash-filter-uuid
logstash-filter-xml
logstash-input-azure_event_hubs
logstash-input-beats
└── logstash-input-elastic_agent (alias)
logstash-input-couchdb_changes
logstash-input-dead_letter_queue
logstash-input-elastic_serverless_forwarder
logstash-input-elasticsearch
logstash-input-exec
logstash-input-file
logstash-input-ganglia
logstash-input-gelf
logstash-input-generator
logstash-input-graphite
logstash-input-heartbeat
logstash-input-http
logstash-input-http_poller
logstash-input-jms
logstash-input-pipe
logstash-input-redis
logstash-input-stdin
logstash-input-syslog
logstash-input-tcp
logstash-input-twitter
logstash-input-udp
logstash-input-unix
logstash-integration-aws
├── logstash-codec-cloudfront
├── logstash-codec-cloudtrail
├── logstash-input-cloudwatch
├── logstash-input-s3
├── logstash-input-sqs
├── logstash-output-cloudwatch
├── logstash-output-s3
├── logstash-output-sns
└── logstash-output-sqs
logstash-integration-jdbc
├── logstash-input-jdbc
├── logstash-filter-jdbc_streaming
└── logstash-filter-jdbc_static
logstash-integration-kafka
├── logstash-input-kafka
└── logstash-output-kafka
logstash-integration-logstash
├── logstash-input-logstash
└── logstash-output-logstash
logstash-integration-rabbitmq
├── logstash-input-rabbitmq
└── logstash-output-rabbitmq
logstash-integration-snmp
├── logstash-input-snmp
└── logstash-input-snmptrap
logstash-output-csv
logstash-output-elasticsearch
logstash-output-email
logstash-output-file
logstash-output-graphite
logstash-output-http
logstash-output-jdbc
logstash-output-lumberjack
logstash-output-nagios
logstash-output-null
logstash-output-pipe
logstash-output-redis
logstash-output-stdout
logstash-output-syslog
logstash-output-tcp
logstash-output-udp
logstash-output-webhdfs
logstash-patterns-core在线安装
$ bin/logstash-plugin install logstash-output-jdbc
$ bin/logstash-plugin install logstash-output-syslog
Using bundled JDK: /home/vagrant/wk/demo-01-logstash/logstash-9.2.1/jdk
Validating logstash-output-syslog
Resolving mixin dependencies
Installing logstash-output-syslog
Installation successful相关信息
检查并修改镜像源
# 1
$ gem sources -l
*** CURRENT SOURCES ***
https://rubygems.org/
$ gem sources --add https://gems.ruby-china.com/ --remove https://rubygems.org/
https://gems.ruby-china.com/ added to sources
https://rubygems.org/ removed from sources
$ cat ~/.gemrc
---
:backtrace: false
:bulk_threshold: 1000
:sources:
- https://gems.ruby-china.com/
:update_sources: true
:verbose: true
:concurrent_downloads: 8# 2
$ sed -i 's@https://rubygems.org@https://gems.ruby-china.com@g' ${LOGSTASH_HOME}/Gemfile离线安装
在实际应用过程中有些生产环境是封闭的网络环境,没法连接外网。这时候就需要离线安装插件。
说离线安装实际就是在一个有网络的环境下将插件装好,然后再装到离线环境中。 这里有两种方式:
- 全量打包:一种就是在有网络的环境下将插件装好,将整个logsash包离线拷到生产环境。
- 插件打包:一种就是在有网络的环境下将插件装好,将部分logstash的需要离线安装的插件离线到生产环境,然后进行离线安装。
离线插件包制作、安装
离线插件包制作
$ bin/logstash-plugin prepare-offline-pack --output logstash-output-syslog.zip logstash-output-syslog
Using bundled JDK: /home/vagrant/wk/demo-01-logstash/logstash-9.2.1/jdk
Offline package created at: logstash-output-syslog.zip
You can install it with this command `bin/logstash-plugin install file:///home/vagrant/wk/demo-01-logstash/logstash-9.2.1/logstash-output-syslog.zip`
$ ll | grep zip
-rwxrwx---. 1 vagrant vagrant 41727 Nov 23 07:08 logstash-output-syslog.zip离线插件包安装
$ bin/logstash-plugin install file:///home/vagrant/wk/demo-01-logstash/logstash-9.2.1/logstash-output-syslog.zip
Installing file: /home/vagrant/wk/demo-01-logstash/logstash-9.2.1/logstash-output-syslog.zip
Install successful
$ bin/logstash-plugin list | grep syslog
Using bundled JDK: /home/vagrant/wk/demo-01-logstash/logstash-9.2.1/jdk
logstash-filter-syslog_pri
logstash-input-syslog
logstash-output-syslog启动
命令行
-e '配置'
提示
可以不写任何具体配置,直接运行 bin/logstash -e '' 效果等同于 bin/logstash -e 'input { stdin {} } output { stdout {} }'。
--config '配置文件路径' 或 -f '配置文件路径'
真实运用中,我们会写很长的配置,甚至可能超过 shell 所能支持的 1024 个字符长度。所以我们必把配置固化到文件里,然后通过 这样的形式来运行。 如: bin/logstash -f agent.conf
此外,logstash 还提供一个方便我们规划和书写配置的小功能。 你可以直接用 bin/logstash -f /etc/logstash.d/ 来运行。logstash 会自动读取 /etc/logstash.d/ 目录下所有的文本文件,然后在自己内存里拼接成一个完整的大配置文件,再去执行。
--configtest 或 -t
意即测试。用来测试 Logstash 读取到的配置文件语法是否能正常解析。Logstash 配置语法是用 grammar.treetop 定义的。尤其是使用了上一条提到的读取目录方式的读者,尤其要提前测试。
--log 或 -l
意即日志。Logstash 默认输出日志到标准错误。生产环境下你可以通过 bin/logstash -l logs/logstash.log 命令来统一存储日志。
--filterworkers 或 -w
意即工作线程。Logstash 会运行多个线程。你可以用 bin/logstash -w 5 这样的方式强制 Logstash 为过滤插件运行 5 个线程。
配置
logstash.yaml
worker相关配置:
pipeline.workers: 该参数用以指定Logstash中执行filter和output的线程数。 当如果发现CPU使用率尚未达到上限,可以通过调整该参数,为Logstash提供更高的性能。 建议将Worker数设置适当超过CPU核数可以减少IO等待时间对处理过程的影响。 实际调优中可以先通过-w指定该参数,当确定好数值后再写入配置文件中。pipeline.batch.size: 该指标用于指定单个worker线程一次性执行flilter和output的event批量数。 增大该值可以减少IO次数,提高处理速度,但是也以为这增加内存等资源的消耗。 当与Elasticsearch联用时,该值可以用于指定Elasticsearch一次bluck操作的大小。pipeline.batch.delay: 该指标用于指定worker等待时间的超时时间,如果worker在该时间内没有等到pipeline.batch.size个事件,那么将直接开始执行filter和output而不再等待。
pipeline
语法
Logstash 设计了自己的 DSL —— 包括有区域、注释、数据类型(布尔值/字符串/数值/数组/哈希)、条件判断、字段引用、等。
数据类型
Logstash 支持少量的数据值类型:
- bool
debug => true - string
host => "hostname" - number
port => 514 - array
match => ["datetime", "UNIX", "ISO8601"] - hash
options => { key1 => "value1", key2 => "value2" }
区段(section)
Logstash 用 {} 来定义区域。 区域内可以包括插件区域定义,你可以在一个区域内定义多个插件。 插件区域内则可以定义键值对设置。示例如下:
input {
stdin {}
syslog {}
}字段引用(field reference)
如果想在 Logstash 配置中使用字段的值,只需要把字段的名字写在中括号 [] 里就行了,这就叫字段引用。
[geoip][location][0] # 从 geoip 里这样获取 longitude 值
[geoip][location][-1] # 倒序下标,即获取数组最后一个元素的值
"the longitude is %{[geoip][location][0]}" # 变量内插,在字符串里使用字段引用条件判断(condition)
表达式支持下面这些操作符:
- equality, etc:
==,!=,<,>,<=,>= - regexp:
=~,!~ - inclusion:
in,not in - boolean:
and,or,nand,xor - unary:
!()
通常来说,你都会在表达式里用到字段引用。比如:
if "_grokparsefailure" not in [tags] {
} else if [status] !~ /^2\d\d/ and [url] == "/noc.gif" {
} else {
}常用插件
INPUT
todo file todo http todo redis
FILTER
todo date
todo grok 【重要】 todo grok语法
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}todo dissect —— 基于分隔符原理解析数据,解决grok解析时消耗cpu资源过多问题。direct语法简单,能处理的场景也比较有限。(它只能处理格式相似,且有分隔符的字符串。)
todo mutate —— 最频繁使用的插件,可以对字段进行各种操作,比如重命名、删除、替换、更新等
todo json
todo 标记事件的某方面属性。可以有多个标签,可以通过过滤器中 add_tag/remove_tag/add_field/remove_field 匹配成功时生效
todo geoip —— 根据ip地址提供对应的地域信息,包括国别、省市、经纬度等,对于可视化地图和区域统计非常有用。 todo 依赖的数据库,是否联网
filter {
geoip {
source => "clientip"
}
}OUTPUT
todo redis todo kafka
todo elasticsearch todo https://www.elastic.co/guide/en/logstash/8.18/logstash-modules.html
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}查询Elasticsearch确认数据是否正常上传(注意替换查询语句中的日期)
curl -XGET 'http://172.16.16.17:9200/logstash-2018.10.09/_search?pretty&q=response=200'
密钥库
参考: https://www.elastic.co/docs/reference/logstash/keystore
todo https://www.elastic.co/docs/reference/logstash/keystore
例子
syslog to syslog
nginx ------------------> Logstash ----------------> nginx
rsyslog [INPUPTS -> FILTERS -> OUTPUTS] rsyslog
DataSource Logstash Pipeline DataReceive# 把514端口输入的syslog日志输出到目标地址514端口
$ vi ${LOGSTASH_HOME}/test-pipeline.conf
input {
stdin{
type => "test-log"
}
syslog{
type => "test-log"
port => 514
}
}
output
{
stdout {
codec => rubydebug
}
syslog{
host => "192.168.2.185"
port => 514
}
}# 对配置文件进行检查
bin/logstash -f test-pipeline.conf --config.test_and_exit
# 启动(包含动态重载配置功能)
bin/logstash -f test-pipeline.conf --config.reload.automatic提示
可以用udpsender构造syslog数据: 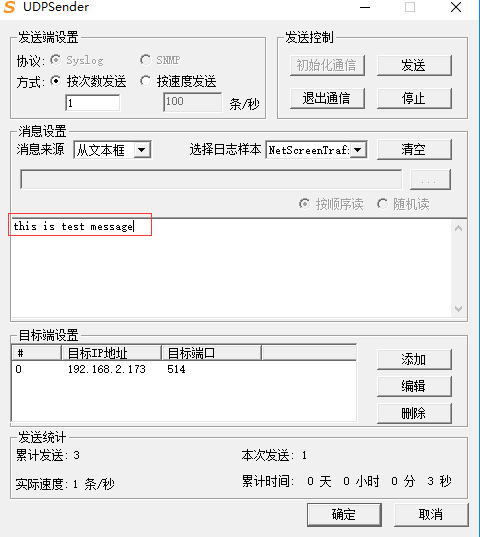
syslog to elasticsearch
nginx ------------------> Logstash ----------------> Elasticsearch
rsyslog [INPUPTS -> FILTERS -> OUTPUTS]
DataSource Logstash Pipeline略
syslog to kafka to mysql/elasticsearch
数据先放到kafka队列里缓存消峰,然后从kafka队列里读取数据到mysql或者其他存储系统中。
nginx ------------------> Logstash ----------------> kafka ------------------> Logstash ----------------> MySQL/Elasticsearch
rsyslog [INPUPTS -> FILTERS -> OUTPUTS] [INPUPTS -> FILTERS -> OUTPUTS]
DataSource Logstash Pipeline Logstash Pipeline略
syslog to logstash with geoip to syslog
采集原始日志以后,需要对原始日志进行调整合补齐,比如最常见的是根据IP来补齐IP的经纬度等信息。
http的API接口
↑
nginx ------------------> Logstash ----------------> nginx
rsyslog [INPUPTS -> FILTERS -> OUTPUTS] rsyslog
DataSource Logstash Pipeline DataReceive这里就可以用logstash的geotip,也可以用其他的外部API接口,为了更具代表性的说明,这里调用的是第三方的http接口(http://ip-api.com/json/),这个接口也是可以自己定义的。
input {
stdin { }
syslog {
port => "514"
}
}
filter {
grok{
#匹配获取IP
match => {"message" => "%{IPV4:ip}"}
}
http {
#调用外部接口获取IP的详细信息
url => "http://ip-api.com/json/%{ip}"
verb => "GET"
add_field => {
"new_field" => "new_static_value"
}
body => ""
}
mutate {
# 修改数据插件
# rename 重命名字段名
# add_field 添加字段
# remove_field 删除字段
# replace 替换字段的值
# gsub 修改字段值的字符
# convert 修改字段值的数据类型
# split 拆分字段
# merge 合并字段
# 写法1 使用中括号[]
# rename => ["old_field" => "new_field"]
# 写法2 使用大括号{}
# rename => {"old_field" => "new_field"}
# add_field => {
# "f1" => "field1"
# "f2" => "field2"
# }
# remove_field => ["message", "@version"]
# convert => {"filedName" => "string"}
# gsub => ["fieldName", "/", "_"]
# e.g.
replace => {
#这里对原始日志数据进行补全,如加了新的字段及从接口中获取的信息
"message" => "%{message}|%{ip}: My new message|%{new_field}|%{[body][as]}"
}
}
# 条件标签
# 在日志文件路径包含 access 的条件下添加标签的内容
if [path] =~ "access" {
mutate {
add_tag => ["Nginx Access Log"]
}
}
if [path] == "/var/log/nginx/error.log" {
mutate {
add_tag => ["Nginx Error Log"]
}
}
}
output {
stdout { }
syslog {
host => "192.168.2.173"
port => "7514"
}
}# 对配置文件进行检查
$ bin/logstash -f test-pipeline.conf --config.test_and_exit
# 启动
$ bin/logstash -f test-pipeline.conf --config.reload.automatic
1.1.1.1
{
"@timestamp" => 2025-11-30T15:54:39.327387337Z,
"message" => "1.1.1.1|1.1.1.1: My new message|new_static_value|AS13335 Cloudflare, Inc.",
"@version" => "1",
"host" => {
"hostname" => "demo-se-elk"
},
"event" => {
"original" => "1.1.1.1"
},
"body" => {
"timezone" => "Asia/Hong_Kong",
"lon" => 114.1693,
"status" => "success",
"country" => "Hong Kong",
"regionName" => "Central and Western District",
"city" => "Hong Kong",
"lat" => 22.3193,
"isp" => "Cloudflare, Inc",
"as" => "AS13335 Cloudflare, Inc.",
"zip" => "",
"query" => "1.1.1.1",
"countryCode" => "HK",
"region" => "HCW",
"org" => "APNIC and Cloudflare DNS Resolver project"
},
"new_field" => "new_static_value",
"ip" => "1.1.1.1"
}其他
对比flume
- Logstash比较偏重于字段的预处理,在异常情况下可能会出现数据丢失,只是在运维日志场景下,一般认为这个可能不重要; 而Flume偏重数据的传输,几乎没有数据的预处理,仅仅是数据的产生,封装成event然后传输; 传输的时候flume比logstash多考虑了一些可靠性。因为数据会持久化在channel中,数据只有存储在下一个存储位置(可能是最终的存储位置,如HDFS; 也可能是下一个Flume节点的channel),数据才会从当前的channel中删除。这个过程是通过事务来控制的,这样就保证了数据的可靠性。
- Logstash有几十个插件,配置比较灵活,flume强调用户自定义开发;
- Logstash的input和filter还有output之间都存在buffer,进行缓冲;Flume直接使用channel做持久化
- Logstash性能以及资源消耗比较严重,且不支持缓存;
参考
- logstash简明实用教程 - https://www.cnblogs.com/xiejava/p/12911453.html
- ELKstack 中文指南 - https://elkguide.elasticsearch.cn/
- Logstash 入门 - https://elastic.ac.cn/docs/reference/logstash/getting-started-with-logstash