Redis 配置和部署策略
配置模板
完整配置在源码目录 redis.conf 文件中:
常用配置注解(5.0.8)
# Redis configuration file example.
#
# Note that in order to read the configuration file, Redis must be
# started with the file path as first argument:
#
# ./redis-server /path/to/redis.conf
# Note on units: when memory size is needed, it is possible to specify
# it in the usual form of 1k 5GB 4M and so forth:
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# units are case insensitive so 1GB 1Gb 1gB are all the same.
################################## INCLUDES ###################################
# 指定包含其他的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件
# 而同时各个实例又拥有自己的特定配置文件
#
# include /path/to/local.conf
# include /path/to/other.conf
################################## MODULES #####################################
# 略
################################## MODULES #####################################
# 绑定的主机地址
# bind 127.0.0.1 #限制redis只能本地访问
bind 127.0.0.1
# protected-mode no #默认yes,开启保护模式,限制为本地访问
# 端口号
port 6379
# 客户端连接超时
timeout 0
# redis默认不是以守护进程方式(后台方式)进行
# yes 更换为守护进程开启💡改为yes会使配置文件方式启动redis失败💡
# Redis采用的是单进程多线程的模式。
# 在守护进程模式下(daemonize yes),redis会在后台运行,并将进程pid号写入至redis.conf选项pidfile设置的文件中,此时redis将一直运行,除非手动kill将该进程关闭。
# 而当不是守护进程时(daemonize no),开启进程的当前界面将进入redis命令行界面,exit强制退出、或者关闭连接工具(putty,xshell等)都会导致redis进程退出。
daemonize no
# 当redis以守护进程方式运行,redis默认把pid写入pidfile指定的文件
pidfile /var/run/redis_6379.pid
# 日志级别
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
loglevel notice
# 日志记录方式,默认为标准输出
# 如果配置为守护京进程方式运行,而这里有配置标准输出,则日志将被发送给/dev/null
# logfile ""
logfile stdout
# 设置数据库的数量
# 默认数据库为0,可以使用 SELECT <dbid> 命令在连接上指定数据库id
# (后面会讲为什么是16个,每个库有什么用)
databases 16
################################ SNAPSHOTTING ################################
# 指定在多长时间内,有多少次更新操作,就会将数据同步到数据文件,可以多个条件配合
# save <seconds> <changes>
# 默认分表表示为:
# 900秒内有1个更改,300秒内有10个更改,60秒内有10000个更改
save 900 1
save 300 10
save 60 10000
# 指定存储至本地数据库时是否压缩数据,默认为yes
# redis采用LZF(压缩算法)
# 如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes
# 指定本地数据库文件名,默认为dump.rdb
dbfilename dump.rdb
# 指定本地数据库存放目录
dir ./
################################# REPLICATION #################################
# 设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
#
# Master-Replica replication. Use replicaof to make a Redis instance a copy of
# another Redis server. A few things to understand ASAP about Redis replication.
#
# +------------------+ +---------------+
# | Master | ---> | Replica |
# | (receive writes) | | (exact copy) |
# +------------------+ +---------------+
#
# 1) Redis replication is asynchronous, but you can configure a master to
# stop accepting writes if it appears to be not connected with at least
# a given number of replicas.
# 2) Redis replicas are able to perform a partial resynchronization with the
# master if the replication link is lost for a relatively small amount of
# time. You may want to configure the replication backlog size (see the next
# sections of this file) with a sensible value depending on your needs.
# 3) Replication is automatic and does not need user intervention. After a
# network partition replicas automatically try to reconnect to masters
# and resynchronize with them.
#
# replicaof <masterip> <masterport>
# 当master服务设置了密码保护时,slav服务连接master的密码
#
# If the master is password protected (using the "requirepass" configuration
# directive below) it is possible to tell the replica to authenticate before
# starting the replication synchronization process, otherwise the master will
# refuse the replica request.
#
# masterauth <master-password>
################################## SECURITY ###################################
# 设置Redis连接密码,如果设置了连接密码,客户端在连接Redis时,需要通过 AUTH <password>命令提供密码
# 默认关闭
#
# requirepass foobared
################################### CLIENTS ####################################
# 设置同一时间最大客户端连接数
# 默认无限制,Redis可以同时打开客户端连接数为Redis进程可以打开的最大文件描述符数
# 如果设置maxclients 0,表示不做限制。
# 当客户端连接数达到限制时,Redis会关闭新的连接并向客户端返回max number of clients reached 错误信息
#
# maxclients 10000
############################## MEMORY MANAGEMENT ################################
# 指定Redis最大内存限
# Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key。
# 当此方法处理后,仍然到达最大内存的设置,将无法再进行写入操作,但仍然可以进行读取操作。
# Redis新的vm机制,会把key存放到内存,value会存放到swap区
# 默认值官方没说
#
# maxmemory <bytes>
# 指定内存维护策略(下面马上讲)
#
# MAXMEMORY POLICY: how Redis will select what to remove when maxmemory
# is reached. You can select among five behaviors:
#
# volatile-lru -> Evict using approximated LRU among the keys with an expire set.
# allkeys-lru -> Evict any key using approximated LRU.
# volatile-lfu -> Evict using approximated LFU among the keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
# volatile-random -> Remove a random key among the ones with an expire set.
# allkeys-random -> Remove a random key, any key.
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# noeviction -> Don't evict anything, just return an error on write operations.
#
# LRU means Least Recently Used
# LFU means Least Frequently Used
#
# Both LRU, LFU and volatile-ttl are implemented using approximated
# randomized algorithms.
#
# Note: with any of the above policies, Redis will return an error on write
# operations, when there are no suitable keys for eviction.
#
# At the date of writing these commands are: set setnx setex append
# incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd
# sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby
# zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby
# getset mset msetnx exec sort
#
# The default is:
#
# maxmemory-policy noeviction
############################# LAZY FREEING ####################################
# 略
############################## APPEND ONLY MODE ###############################
# 指定是否每次更新后进行日志记录
# Redis在默认情况下是异步的把数据库写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。
# 因为,redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。
# 默认为 no
appendonly no
# 指定更新日志名,默认为appendonly.aof
# The name of the append only file (default: "appendonly.aof")
appendfilename "appendonly.aof"
# 指定更新日志条件,共有3个可选值:
# no:表示等操作系统进行数据缓存同步到磁盘(快)
# always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全)
# everysec:表示每秒同步一次(折中方案,默认值)
# 请选择:
# appendfsync always
appendfsync everysec
# appendfsync no
################################ LUA SCRIPTING ###############################
# 略
################################ REDIS CLUSTER ###############################
# 略
################################## SLOW LOG ###################################
# 略
################################ LATENCY MONITOR ##############################
# 略
############################### ADVANCED CONFIG ###############################
# 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
# 指定是否激活重置哈希,默认为开启
# (后面再介绍Redis的哈希算法)
activerehashing yes
########################### ACTIVE DEFRAGMENTATION #######################
# 略重点看几个配置:(5.0.8)
bind 127.0.0.1── 注释掉这部分,这是限制 redis 只能本地访问protected-mode no── 默认 yes,开启保护模式,限制为本地访问daemonize no── 默认 no,改为 yes 意为以守护进程方式启动,可后台运行,除非 kill 进程(改为 yes 会使配置文件方式启动 redis 失败)databases 16── 数据库个数(可选)dir ./── 输入本地 redis 数据库存放文件夹(可选)appendonly yes── redis 持久化(可选)
安全配置
todo
- redis 安全 - https://redis.io/docs/management/security/
- antirez 关于 Redis 安全性的几件事 http://antirez.com/news/96
内存维护策略
最大缓存配置: 在 redis 中,允许用户设置最大使用的内存大小:
maxmemory 512G
maxmemory-policy allkeys-lru注意
Redis 官方给的警告,当内存不足时,Redis 会根据配置的缓存策略淘汰部分 keys ,以保证写入成功。 当无淘汰策略时或没有找到适合淘汰的 key 时, Redis 直接返回 out of memory 错误。
为了增加内存使用率,对于存在内存中但 “用不着的” 数据块 Redis 倾向于而将其移出内存而腾出内存来加载另外的数据。
如何判断数据是否 “用不着”,Redis 给出 6 种数据淘汰策略:
volatile-lru:LRU(Least Recently Used,最近最久未使用算法)指设定的超时时间的数据中,删除最不常用的数据allkeys-lru:查询所有的 key 中最近最不常用的数据进行删除 (这是应用最为广泛的策略)volatile-random:在已经设定了超时的数据中随机删除allkeys-random:查询所有的 key,之后随机删除volatile-ttl:查询全部设置定超时时间的数据之后,排序,将马上要过期的数据进行删除。noeviction(默认):如果设置为该属性,则不会进行删除操作,如果内存溢出,则报错返回。volatile-lfu:LFU(Least Frequently Used ,最近最少使用算法)指从所有配置了过期时间的键中驱逐使用的平率最少的键 (也是一种常见的缓存算法)allkeys-lfu:从所有键中驱逐使用频率最少的键 (4.0 后新增策略)
配置:
todo持久化策略
持久化方案有两种: (参考: link)
| 定时快照(snapshot) (Redis 默认的持久化方式) | 基于语句追加(aof,append only file,只追加日志文件) | |
|---|---|---|
| 策略 | 定时将数据全量写入 *.rdb 磁盘文件 | 只将变化的数据写入 *.aof 磁盘文件 |
| 优点 | 保存数据快、还原数据快 |
|
| 缺点 | 备份过程需要双倍内存 |
|
RDB:定时快照(snapshot)
定时将所有数据写入磁盘中的 *.rdb (如 dump.rdb)结尾的文件中。 这种方式也被称为 RDB(Redis DataBase) 方式。
配置文件:
# 指定存储至本地数据库时是否压缩数据,默认为yes
# redis采用LZF(压缩算法)
# 如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes
# 指定本地数据库文件名,默认为dump.rdb
dbfilename dump.rdb
# 指定本地数据库存放目录,默认 /data
dir ./触发方式:
服务端根据配置定时/定量触发
save 900 1 # 每 900 秒(15 分钟)至少 1 个 key 发生变化,产生快照 save 300 10 # 每 300 秒(5 分钟)至少 10 个 key 发生变化,产生快照 save 60 10000 # 每 60 秒(1 分钟)至少 10000 个 key 发生变化,产生快照客户端触发:通过
BGSAVE(调用 fork 进程归档) 和SAVE(调用当前进程归档) 命令服务器正常关闭
redis-cli shutdown
AOF:只追加日志文件(append only file)
- 在使用 aof 持久化方式时,redis 会将每一个收到的写命令都通过 write 函数追加到文件中(默认是
appendonly.aof)。 - 当 redis 重启时,会通过重新执行文件中保存的写命令来在内存中重新构建整个数据库的内容。
配置文件:
appendonly yes # 启动 aof 持久化
appendfsync always/everysec/no
# always 收到命令就立即写入磁盘;最慢,但是保证完全的持久化
# everysec (默认,推荐)每秒中写入磁盘一次;在性能和持久化方面做了很好的折中
# no 有操作系统决定合适写入AOF(如正常关闭时才开始持久化);性能最好,持久化没有保证AOF 重写机制: AOF 的方式带来另外一个问题,随着持久化次数增加,持久化文件会变得越来越大。 但注意到其中有可压缩空间,如 set a {newValue} 命令执行 100 次,只需要记录最后一次命令。 由此 Redis 提供了 AOF ReWriter 机制(AOF 重写机制),来在一定程度上减少 AOF 文件的体积。
触发重写方式:
客户端触发:执行
BGREWRITEAOF命令服务器配置自动触发:
auto-aof-rewrite-percentage 100 # AOF 文件体积比上次重写大 100% (一倍) auto-aof-rewrite-min-size 64mb # AOF 文件体积大于 64mb
高可用(High Availability)策略
避免单节点故障导致服务不可用,为此 Redis 提供如下高可用策略架构:
- 主从复制:用来解决数据的冗余备份,从节点用来同步数据
- 心跳机制、哨兵:故障转移策略
主从复制机制
Redis 主从复制:
+ Master
├─ Slave-1
└─ Slave-2提示
从节点在升级到主节点前,都是只读的(2.6 版本后)。 在从节点修改,会收到报错 “READONLY You can't write against a read only replica.”。
# master
port 6379
bind 0.0.0.0
# slave1
port 6380
bind 0.0.0.0
slaveof 127.0.0.1 6379
# slave2
port 6381
bind 0.0.0.0
slaveof 127.0.0.1 6379# --slaveof 或者 --replicaof
/usr/local/redis/bin/redis-server /usr/local/redis/redis.conf --port 6380 --slaveof 127.0.0.1 6379# 不是任何的从
slaveof no one
# 指定从属的主服务器
slaveof ip地址 端口号如果从节点无法访问主节点(提示:master_link_status:down),且地址、端口、认证信息均无误,考虑是否开启防火墙:
# 端口看你自己情况
firewall-cmd --zone=public --add-port=3679/tcp --permanent
firewall-cmd --reload主从复制的数据同步阶段(psync)分两步:
- 全量复制:主节点生成 RDB 文件,发送给从节点进行数据恢复
- 部分复制:主节点将新数据保存“复制缓冲区”,待从节点完成 RDB 文件恢复后,将缓冲区信息发送给从节点,进行差异同步
repl-backlog-size 1mb # 调整复制缓存区大小
slave-server-stale-data yes|no # 主从复制过程中,从服务器是否响应客户端请求,建议设置为 no提示
估算 repl-backlog-size 最优值:
- 测算 master 到 slave 的重连平均时长
second - 获取 master 平均每秒产生写命令数据总量
write_size_per_second - 最优复制缓冲区空间 = 2 *
second*write_sieze_per_second
心跳机制:主从双方使用心跳机制确保双方连接在线
- master 定期使用
ping命令判断 slave 是否在线 (通过 INFO replication 获取 slave 最后一次连接时间间隔,lag 项维持在 0 或 1 视为正常) - slave 使用
REPLCONF ACK [offset]命令向 master 汇报自己的复制偏移量
########################
# master 配置
########################
repl-ping-slave-period # ping slave 的周期,默认10s
repl-timeout # ping slave 的等待时间,默认60s
# 当 slave 多数掉线或延迟过高时,master 为保障数据稳定性,将拒绝所有信息同步操作
min-slaves-to-write 2 # 最小slave数量
min-slaves-max-lag 8 # 最大延迟8s:::
实验:
- 在主节点更新键值,从节点马上也能查到更新的键值。 —— 符合备份要求
- 关闭主节点,连接主节点的应用无法访问 redis 服务,导致单点异常。 —— 不符合高可用要求
两个好处:
- 读写分离:提高服务器的负载能力,可根据读请求的规模自由增加或减少从库的数量
- 可用性:数据被复制成好几份,一台机器故障,可以快速从其他机器获取数据并回复。
故障转移机制(哨兵机制)
哨兵(Sentinel)机制是 Redis 的高可用解决方案: 由一个或多个 Sentinel 实例组成的 Sentinel 系统可以监视任意多个主服务器,以及这些服务器下属的所有从服务器。 当被监视的主服务器下线后,自动将其下属的从服务器升级为新的主服务器。 简单的说哨兵机制就是带自动故障转移的主从架构。
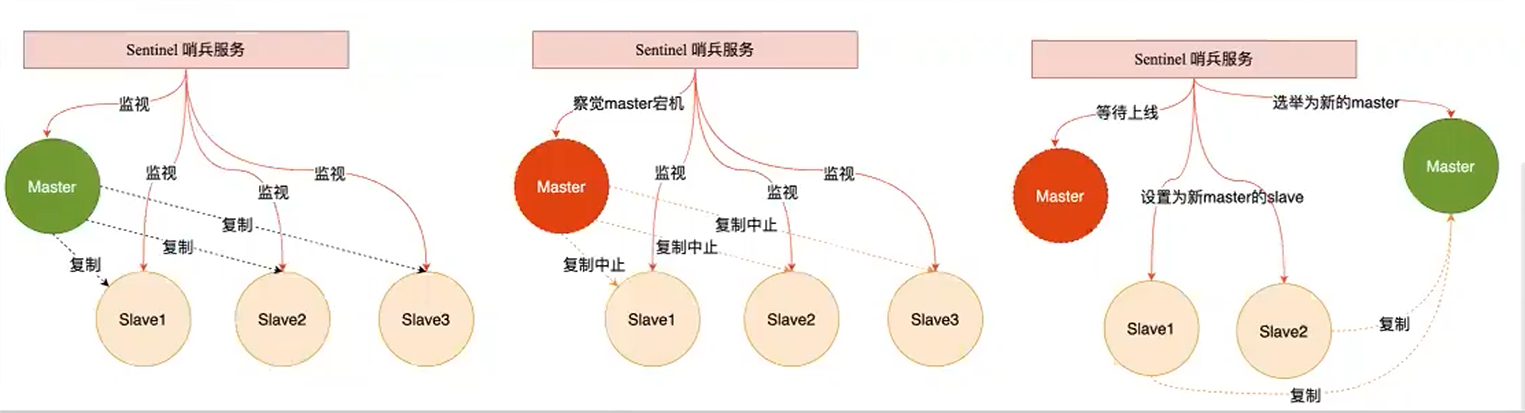
提示
哨兵机制依然无法解决单节点并发压力问题、单节点内存/cpu/磁盘物理上限问题。 解决该问题,需要使用集群机制。
一个哨兵的配置
哨兵配置文件
# sentinel monitor 主从架构标识 master-ip master-port 哨兵数量
sentinel monitor architect-01 192.168.202.206 6379 1启动哨兵
redis-sentinel sentinel.conf提示
程序客户端(Java/Python/...)连接哨兵模式的Redis时,需要配置哨兵的地址和架构。
如 spring boot
spring:
redis:
sentinel:
master: architect-01
nodes: localhost:26379,localhost:26380多个哨兵的配置
注意
多个哨兵的情况下,哨兵数量需要为 “奇数”。 因为,master 节点是通过哨兵间的选举产生的,如果为偶数可能导致多次选举。
哨兵相关配置
todo
集群机制
Redis 在 3.0 后开始支持 Cluster(集群) 模式。
特性:
- 节点自动发现
slave-master选举和容错- 在线分片(sharding shard)
- 等
集群架构说明
概念:
- 槽位(slot) —— 集群模式下,“根据key取value的动作”会先根据key进行CRC16算法计算得到槽位值(slot index)然后到槽位值对应的节点(node)上存取value。
- 节点(node) —— 节点可以是单个redis服务,也可以是“主从复制/哨兵机制”的redis服务。节点数量需要固定,集群会把
[0-16383]slot个槽位(slot)“均匀”分配到每个节点上。 - 集群(cluster) —— 负责检测节点(node)的存活(
ping-pong机制,内部使用二进制协议优化传输速度和带宽),和负责维护槽位(slot)到节点的映射关系。
相关信息
说明:
- 所有redis节点彼此互联(
ping-pong机制) - 节点的fail是通过集群中超过半数的节点检测失败时才生效
- 客户端与redis节点直连,不需要中间proxy层、不需要连接集群所有节点(连接集群中任何一个节点即可)
redis-cluster把所有的节点映射到[0-16383]slot上,cluster负责维护node<->slot<->value
集群搭建
# 说明:搭建redis集群的节点数量最好是“奇数”,所以最少情况:“主节点”3个、“从节点”3个,至少需要启动6个redis服务。
# 简化:在一个vm上启6个redis服务
# 说明:redis集群依赖ruby语言脚本
# 1. 安装redis集群依赖:ruby、....
yum install -y ruby rubygems
gem install redis
# libyaml-0.1.4-11.el7_0.x86_64.rpm
# ruby-2.0.0.648-34.el7_6.x86_64.rpm
# ruby-irb-2.0.0.648-34.el7_6.x86_64.rpm
# ruby-libs-2.0.0.648-34.el7_6.x86_64.rpm
# rubygem-bigdecimal-1.2.0-34.el7_6.x86_64.rpm
# rubygem-io-console-0.4.2-34.el7_6.x86_64.rpm
# rubygem-json-1.7.7-34.el7_6.x86_64.rpm
# rubygem-psych-2.0.0-34.el7_6.x86_64.rpm
# rubygem-rdoc-4.0.0-34.el7_6.x86_64.rpm
# rubygems2.0.14.1-34.el7_6.x86_64.rpm
# redis-3.2.1.gem场景:节点自动发现
todo
场景:故障转移
todo 参考哨兵机制
场景:节点重新分配(sharding shard)
所谓“重新分配”就是重新分配hash槽(slot)。
触发条件:
- 节点数量变更(增加/减少)
todo
问题:缓存一致性问题
todo
待整理
todo
- lua 脚本
Redis 2.6 版本通过内嵌支持 Lua 环境。 执行脚本通常命令为: EVAL
Redis 有内置复制、Lua 脚本、LRU 收回、事务以及不同级别磁盘持久化功能,同时通过 Redis Sentinel 提高可用性、通过 Redis Cluster 提供自动分区功能。
todo