JDK 集合功能
2024年6月28日大约 3 分钟
stream
参考:
- guava collections
- Java 中的流、并行流 - Java Stream API | Parallel Streams - https://www.bilibili.com/video/BV1Vi421C73n/
创建
// 创建
List.of().stream()
Arrays.stream()
Stream.of()
Stream.builder().add()....build();
IntStream.of()
// 生成/无限
Stream.iterate(0, n->n<=10, n->n+1) // 遍历
Stream.generate(() -> "hello world").limit(5) // 无限生成,but limit 5
IntStream.boxed() // 无限流
new Random().ints(5).forEach(System.out::println) // 随机
// 文件流需要 close
Path path = Paths.get("file.txt");
try (Stream<String> lines = Files.lines(path)) {
lines.forEach(System.out::println);
} catch(IOException e) {
e.getStackTrace();
}处理:排序/合并/过滤
// 跳过/限制/过滤
Stream.of().skip(2).limit(20).filter()
// 排序/去重
Stream.of().distinct()
Stream.of().sorted(Comparator.comparingInt(Stream::length).reversed())
// 合并
Stream.concat(stream1, stream2) // [...stream1, ...stream2]
// 转换
Stream.of().map() // list -> list
Stream.of().flatMap() // list<list> -> flat list
Stream.of().mapToInt() // ...
// 并行
Stream.of().parallel()
List.of().parallelStream()聚合
// 搜索
xxMatch
findXxx
// 聚合(Aggregation)
count
max straem().max(Comparator.comparingInt(Person::getAge))
min
average
sum
// Collection
collection
// -- toList / toSet
// -- toMap
// -- summary
IntSummaryStatistics ageSummary = people.stream().collect(Collectors.summarizingInt(Person::getAge));
ageSummary.getAverage();
ageSummary.getMax();
// -- of list
ArrayList<Person> collect = people.stream().collect(Collector.of(
() -> new ArrayList<>(),
(list, person) -> { // Accumulator:定义数据如何添加
list.add(person);
},
(left, right) -> { // Combiner:定义两个流如何合并
left.addAll(right);
return left;
},
Collector.Characteristics.IDENTITY_FINISH // Characteristics 特性:IDENTITY_FINISH=累加器结果作为最终结果,无需通过额外的Finisher完成器、CONCURRENT、UNORDERED
));
// -- of map
HashMap<String, List<Person>> collect = people.stream().collect(Collector.of(
HashMap::new,
(map, person) -> { // 合并同键
map.computeIfAbsent(person.getCountry(), ArrayList::new).add(person);
},
(left, right) -> { // 合并两个 map
right.forEach((key, value) -> left.merge(key, value, (list1, list2) -> {
list1.addAll(list2)
return list1;
}));
},
Collector.Characteristics.IDENTITY_FINISH // 对结果进行操作,如: map -> map.size() 返回 int
))
// Iteration
forEach
reduce (Reduction) String joinedName = people.stream().map(Person::getName).reduce("", (a, b) -> a + "," + b);并行(parallel)
借助多核处理器的并行计算能力,加速数据处理,适合大型数据集或计算密集型任务。
工作流程:
- 并行流在开始时,由 Spliterator 分割迭代器将数据分割成多个片段
- 分割过程一般采用递归方式动态进行,以平衡子任务的工作负载、提高资源利用率
- 然后 ForkJoin 框架将这些数据片段分配到多个线程和处理器核心上进行并行处理
- 处理完成后,处理结果被汇总合并
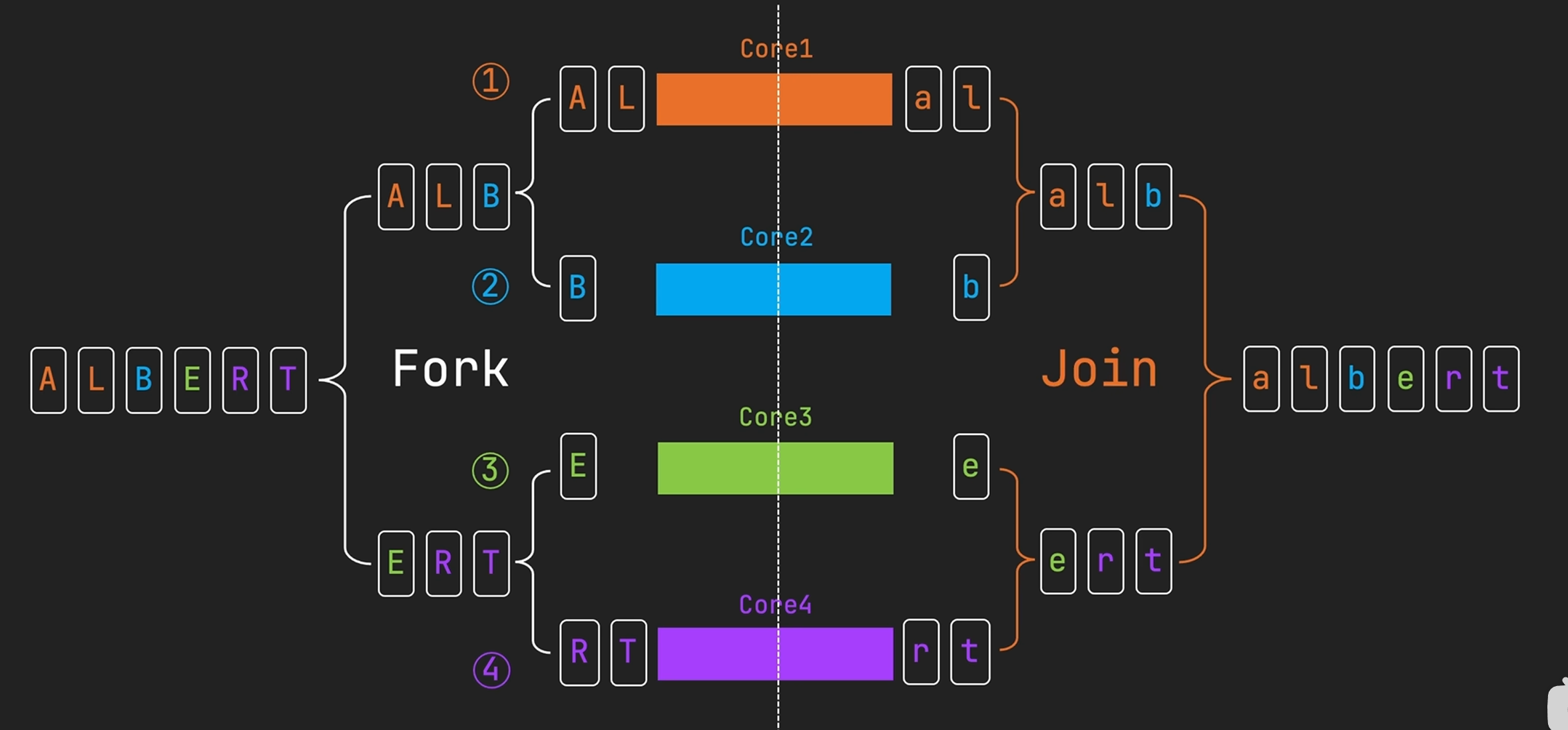
package org.example.thread;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import static org.junit.jupiter.api.Assertions.assertEquals;
@Slf4j
public class CollectionParallelTest {
@Test
void testStreamParallel() {
assertEquals("ABCDE", Stream.of("A", "B", "C", "D", "E").collect(Collectors.joining()));
assertEquals("ABCDE", Stream.of("A", "B", "C", "D", "E").parallel().collect(Collectors.joining())); // 并行但(结果)有序
assertEquals("1A1B1C1D1E", Stream.of("A", "B", "C", "D", "E").parallel().map(s -> "1" + s).collect(Collectors.joining())); // 并行但(结果)有序
assertEquals("1A1B1C1D1E", Stream.of("A", "B", "C", "D", "E").parallel().map(s -> {
log.info(s); // 💡通过日志可见,过程大概率并非有序
return "1" + s;
}).collect(Collectors.joining())); // 💡但最终收集时候是有序的!
}
}更多: Thread 中的 Fork/Join 框架 - link
顺序(结果一致)问题
很多时候我们担心并行流是否导致结果与预期不一致。 判断依据是:计算过程是否依赖元素的出现顺序。
e.g.
// 不依赖出现顺序的聚合操作
max/min a,b = b,a
add a,b = b,a
average a,b = b,a
count a,b = b,a
// 不依赖出现顺序的处理操作
match/find a,b = b,a
findFirst ? 说是不影响
distinct a,b = b,a
sorted a,b = b,a
// 可能出现问题
forEach
reduce a-b != b-a遍历时增删
迭代器 fail-fast 快速失败机制:当迭代器发现(其他代码)增删后,便抛出异常 —— 保证迭代器的独立性和隔离性
List<String> list = new ArrayList();
list.add("hello");
Iterator iterator = list.iterator();
list.add("world"); // 其他代码增删
iterator.next(); // 抛出异常写入时复制(CopyOnWrite,COW) —— 希望迭代期间,能增删和读高性能
参考 link