JDK thread 功能
本文主要整理Java操作线程、协程方式
概念:进程、线程、协程
进程(Process) —— 程序,是系统分配资源的单位
- 范围: 一个系统,多个进程
- 查看: 可通过
ps -ef查看进程列表 - JDK: 通过
java -jar xxx.jar启动的JVM就是一个进程,可通过jps -mlvV查看
线程(Thread)/内核线程(Kernel-Level Thread,KLT) —— 线程,是CPU核心调度的最小单位(一个CPU物理核心只能同时运行一个线程),在程序中共享进程资源,系统提供接口
- 特点: 直接由操作系统内核(Kernel)支持的线程。这种线程由操作系统内核来完成线程切换,操作系统内核通过操纵调度器(Scheduler)对线程进行调度,并负责将线程的任务映射到各个处理器上。
- 范围: 一个进程,多个线程
- JDK: 提供JUC(java.util.concurrent)接口 (JDK的线程接口实现参考openjdk代码:Thread.c/jvm.cpp/thread.cpp/os_linux.cpp)
- 限制: 通过
sysctl kernel.threads-max;cat /proc/sys/kernel/threads-max可查看一个进程可以启动的最大线程数量。可以通过sysctl -w kernel.threads-max=102400;sysctl -p修改。 (当实际线程数量超过上述设置值后,Java 继续创建线程会报错:Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread)
提示
如果要为应用估计工作线程数,可参考如下公式:
- 计算密集型:
线程数 = CPU个数 + 1 - IO密集型:
线程数 = CPU个数 * 2 + 1(还需考虑:吞吐量(tps))
协程(Coroutines)/用户线程(User Thread,UT) —— 程序中让出线程控制权的线程管理方式,不依赖系统接口,一般由开发语言提供接口或开发者自行实现
- 特点: 由程序在内存中管理,创建和销毁的开销相对小,相对相对内核线程更高效
- 范围: 一个线程,多个协程代码
- JDK:
- 在Java 1.2之前,实现Thread接口的是其内部实现的用户线程,由于存在问题之后的版本回归系统的内核线程。
- 在Java 19中实装虚拟线程(Visual Thread)特性,该特性提供了协程接口。 (相比其他语言通过新增
yield语句来控制让出线程控制权,虚拟线程提供的接口和JDK线程接口类似,便于开发者适应)
概念:并发、并行、串行
- 并行 = 多个任务同时执行(同时占用不同的CPU核心时间) (在Java中可以使用
Runtime.getRuntime().availableProcessors()查询当前逻辑处理器核心数) - 串行 = 多个任务先后执行(前后脚占用相同/不同的CPU核心时间)
- 并发 = 多个任务轮流执行(轮流占用CPU核心时间) 时间片、上下文切换:
- 时间片: 为了让一个 CPU 核心并发执行多个线程,操作系统设计了 “时间片” 机制,即 CPU 核心轮流执行不同线程小段时间,让多个任务的状态在一个大时间内总能保持更新。
- 上下文切换: 两个连续的时间片可能给到同一个线程,也可能给到不同的线程。当两个连续的时间片给到不同的线程后,CPU 核心执行到对应时间片时,由于执行的是另外的线程任务,就需要进行线程上下文的切换。
线程(Thread)
线程状态
参考:
在 JAVA 环境中,线程 Thread 有如下几个状态: (💡 通过 Thread.State 查看枚举) (💡 通过 thread.getState() 查看线程状态)
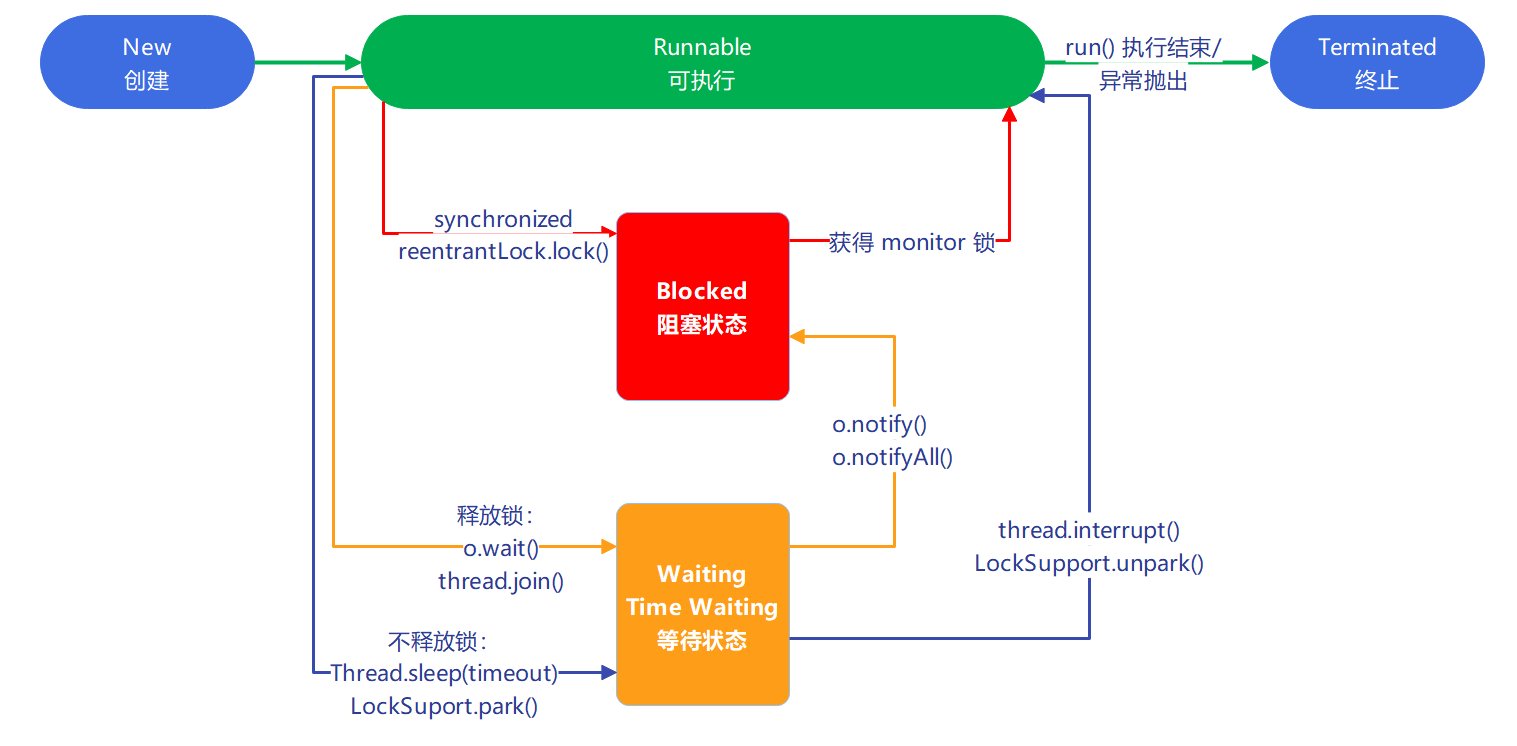
Java线程接口(Thread API)
- start / run
- setName / getName
- sleep (💡 不释放锁)(推荐:TimeUnit) / interrupt / isInterrupted / interrupted
- yield (💡 不释放锁) —— 允许相同优先级其他线程抢占时间片。
- setPriority / getPriority —— 优先级
- join / isAlive —— 等待线程执行完成
- setDaemon —— 守护线程
- setUncaughtExceptionHandler —— 处理未捕获的异常
接口:线程中断(interrupt)
参考:
- 【Java 并发·08】线程中断 interrupt https://www.bilibili.com/video/BV1CM4y157vc/
Java Thread 有如下打断线程相关方法
public void interrupt()打断线程,线程抛出中断异常 (❗ 仅打上中断标记,不保证中断立即执行)public boolean isInterrupted()判断当前线程是否被打断,不清除打断标记public static boolean interrupted()判断当前线程是否被打断,清除打断标记
Thread thread = new Thread(() -> {
while(true) {
System.out.println(Thread.currentThread.isInterrupted()); // true
if (Thread.interrupted()) {
System.out.println(Thread.currentThread.isInterrupted()); // false
break; // 线程中断标记,不会主动中断线程,需要手动结束线程任务
}
System.out.println("定时任务...");
}
});
thread.start();
thread.interrupt(); // 打上线程中断标记提示
Thread.sleep() 中会调用 Thread.interrupted() 判断并消除中断标记
接口:线程异常处理
线程出现异常,异常会被抛出,从而可能导致线程终止。 异常抛出后,先给由 setUncaughtExceptionHandler 方法绑定的处理器处理(如果有注册的话)。
e.g.
Thread thread = new Thread(() -> {
int number = Integer.parseInt("TTT"); // 💡异常
System.out.printf("Number: %d", number);
});
// 设定线程异常处理程序
thread.setUncaughtExceptionHandler(new UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
System.out.println("捕获到线程抛出的异常:");
System.out.printf("线程ID: %s\n", t.getId());
System.out.printf("线程状态: %s\n", t.getState());
System.out.printf("异常信息: %s:%s\n", e.getClass().getName(), e.getMessage());
System.out.println("异常堆栈:");
e.printStackTrace(System.out)
}
});
// 启动线程
thread.start();
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("示例运行结束");线程异常的传递:
- 线程关联的 UncaughtExceptionHandler
- 线程组关联的 UncaughtExceptionHandler
- JVM 默认的 UncaughtExceptionHandler
JMM 内存模型
JMM(Java Memory Model,Java 内存模型)
概念:内存屏障/指令重排/violated可见性
背景: 编译器可能会对指令进行重排序以提高程序性能。这些优化在单线程中通常是安全的,在多线程中可能导致线程间看到的内存状态不一致,从而引发并发问题。 内存屏障(Memory Barrier)是一种用于阻止特定类型的指令重排序的声明,通过控制特定指令的执行顺序,确保内存可见性。
内存屏障的分类:
- LoadLoad —— 确保屏障前的加载指令(Load)先于屏障后的加载指令执行
- StoreStore —— 确保屏障前的存储指令(Store)先于屏障后的存储指令执行
- LoadStore —— 确保屏障前的加载指令(Load)先于屏障后的存储指令执行
- StoreLoad —— 确保屏障前的存储指令(Store)先于屏障后的加载指令执行,同时会刷新CPU缓存,确保存储操作的结果对其他线程可见。(这是最强大的屏障,开销也较大)
JVM实现:
- volatile —— Java编译器生成字节码时,当遇到volatile关键字,会对其修饰的变量的操作指令前插入内存屏障,以确保指令执行顺序和内存可见性。
- 在写操作(Store)后插入StoreStore屏障和StoreLoad屏障,确保:写操作不被重排序到后面的写操作后(避免当前线程ABA),该写操作的结果对其他线程可见(避免其他线程不可见)
- 在读操作(Load)前插入LoadLoad屏障和LoadStore屏障,确保:读操作不被重排序到前面的操作前(避免当前线程AAA),读操作得到最新的内存数据(避免其他线程对该内存的操作不可见)
private static volatile boolean flag = false;
private static int value = 0;
public static void main(String[] args) throws Exception {
Thread thread1 = new Thread(() -> {
value = 100;
flag = true; // volatile写操作,之后会插入StoreStore屏障和StoreLoad屏障
});
Thread thread2 = new Thread(() -> {
while(!flag) { // volatile读操作,之前会插入LoadLoad屏障和LoadStore屏障
// 循环等待flat变为true
}
System.out.println("value = " + value); // 由于有flag的内存屏障,可以读取到flag变化前的变化,所以可以看到value的最新值100
});
thread2.start();
Thread.sleep(100);
thread1.start();
}Java线程安全接口(Thread sync API)
线程安全 = 共享数据符合预期
- 原子性 —— synchronized/Lock接口, atomic类
- 可见性 —— synchronized/Lock接口, atomic类, violated(内存屏障通过避免特定的指令重排确保可见性)
- 有序性 —— synchronized/Lock接口, atomic类, violated(内存屏障避免指令重排)
同步机制包括:
synchronized关键字- Lock 接口
- CountDownLatch 类/CyclicBarrier 类 —— 多线程 join 同步
- Semaphore 类 —— 通过实现经典的信号量机制来实现同步。(Java 支持二进制的信号量和一般信号量)
- Phaser 类 —— 允许控制那些分割成多个阶段的任务的执行。(在所有任务都完成当前阶段之前,任何任务都不能进入下一阶段)
接口:线程锁(synchronized、LockSupport)
todo synchronized
LockSupport 是 java.util.concurrent.locks 包下的一个类,是用来创建锁和其他同步类的基本线程阻塞工具类。
通过 park 和 unpark 方法可以实现线程调度中的 wait(等待) 和 notify(唤醒) 功能。
todo 具体使用方法 https://www.bilibili.com/video/BV1Bw4m1Z7eg?p=47
接口:并发数据结构
Java API 中的常见数据结构(例如 ArrayList、Hashtable 等)并不能在并发应用程序中使用,除非采用外部同步机制。 另外,如果在多线程中修改数据,可能会出现各种异常(例如 ConcurrentModificationException、ArrayIndexOutOfBoundsException、隐性数据丢失、应用陷入死循环 —— 参考 collections 的 COW)
Java API 针对比并发问题,提供了相关的数据结构。大致两类:
- 阻塞型数据结构 —— 含有能够阻塞调用任务的方法
- LinkedBlockingDeque
- LinkedBlockingQueue
- PriorityBlockingQueue —— 基于优先级对元素进行排序的阻塞型队列
- AtomicBoolean/AtomicInteger/AtomicLong/AtomicReference —— 基本数据类型的原子实现
- 非阻塞型数据结构 —— 操作可立即执行,不会阻塞调用的任务。❗ 否则,会返回 null 值或者抛出异常。
- ConcurrentLinkedDeque
- ConcurrentLinkedQueue
- ConcurrentSkipListMap —— 非阻塞型的 NavigableMap
- ConcurrentHashMap
接口:ThreadLocal
略
接口:InheritableThreadLocal
解决 ThreadLocal 无法获取父线程中的 ThreadLocal 的值的问题
InheritableThreadLocal<String> threadLocal = new InheritableThreadLocal<>();
threadLocal.set("test");
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
String value = threadLocal.get();
// ...
}
});
thread.start();
Thread.sleep(1000);提示
无法感知到父线程中途修改 ThreadLocal 的值
InheritableThreadLocal<String> threadLocal = new InheritableThreadLocal<>();
threadLocal.set("test");
for (int i=0; i<10; i++) {
if (i==5) {
threadLocal.set("test5");
}
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
String value = threadLocal.get(); // 依然是 test
// ...
}
}
}为了解决这个问题,可以使用阿里开源组件 TransmittableThreadLocal
接口:原子类(atomic)
在 java.util.concurrent.atomic 包中
| 类型 | 具体类 |
|---|---|
| 基本类型 | AtomicInteger、AtomicLong、AtomicBoolean |
| 引用类型 | AtomicReference、AtomicStampedReference、AtomicMarkableReference (涉及 CAS) |
| 数组类型 | AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray |
| 升级类型 | AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater |
| 累加器 Adder | LongAdder、DoubleAdder |
| 积累器 Accumulator 可自定义累加方式 | LongAccumulator、DoubleAccumulator |
提示
lazySet 不会保证可见性(没有加内存屏障)
问题:ABA 问题
并发场景下,存在上下文数值被其他线程篡改的情况。
这种情况通过 “原子类 + 版本号” 的方式识别。
todo 例子 AtomicStampedReference
问题:死锁问题
- todo 参考: https://www.bilibili.com/video/BV1Xd4y1m7Bs/
- todo demo 哲学家就餐:吃饭围一圈,每人中间间隔一只筷子,优先左手拿筷子,导致右手拿筷子时筷子被占用,导致死锁 —— 处理:顺序释放筷子占用,直到一个人拿到两个筷子
- todo jps 看 PID
- todo jstack 看死锁分析 / jconsole
问题:锁类型
锁类型:悲观锁/互斥锁/阻塞锁
悲观锁 —— 获取锁/释放锁均有 “线程状态的切换”,这会消耗性能
提示
所谓 “线程状态切换” 即: 让没有得到锁资源的线程进入 BLOCK 状态,然后在争夺到锁资源后恢复为 RUNNABLE 状态。 这个过程涉及到操作系统用户模式和内核模式的转换,所以代价比较高。
synchronized 关键字
public synchronized void test() throws InterruptedException { // 💡线程状态切换
this.wait()
this.notify() // 不能指定线程唤醒
}ReentrantLock 类
ReentrantLock lock = new ReentrantLock()
ReentrantLock lock = new ReentrantLock()
lock.lock() // 💡线程状态切换
con.wait()
con.signal()
lock.unlock()锁类型:乐观锁/非阻塞锁
乐观锁 —— 通过系统指令,保证修改某变量状态时是原子性的,从而通过判断该变量状态,判断是否进入锁
自旋锁(spinlock)/CAS(Compare and Swap)
自旋锁是在当前线程上,不停地循环判断原子变量的状态,判断是否进入锁。
提示
自旋锁通过循环将线程卡在某段代码上,从而避免线程状态的改变为 BLOCK,所以响应速度更快。 但当线程数不停增加时,因为每个线程都需要执行,占用 CPU 时间,所以性能会下降明显。 所以只有当线程竞争不激烈,并且保持锁的时间短时,适合使用自旋锁。
e.g.
for(;;) { // 自旋
// 使用操作系统指令保证 compare and set 这两步操作的原子性
if (Unsafe.getUnsafe().compareAndSwapInt()) { // 只有一个线程能进入
// ...
return
}
}or
// 使用了CAS原子操作,lock函数将owner设置为当前线程,并且预测原来的值为空。unlock函数将owner设置为null,并且预测值为当前线程
public class SpinLock {
private AtomicReference<Thread> sign = new AtomicReference<>();
public void lock() {
Thread current = Thread.currentThread();
while (!sign.compareAndSet(null, current)) {}
}
public void unlock() {
Thread current = Thread.currentThread();
sign.compareAndSet(current, null);
}
}锁类型:偏向锁、轻量级锁、重量级锁
synchronized 锁升级问题
在 JDK 1.6 之前,JVM 通过内核态的 管程(Monitor,监视器,对象锁) 来实现 synchronized 锁的互斥。这种锁属于重量级锁,响应效率低。
相关信息
管程(Monitor,监视器)是指管理共享变量操作的过程,让它们支持并发时的线程安全。(简单来说就是两个作用:同步和互斥) Java 中的 synchronized、wait()、notify()、notifyAll() 均是管程技术的一部分。
💡 源码: Hotspot jdk 1.6 c++
在 JDK 1.6 之后,JVM 为了提高锁的获取与释放效率,对 synchronized 的实现进行优化,引入了 “偏向锁” 和 “轻量级锁”。 (此时,锁有四种级别,级别从低到高依次为:无锁、偏向锁、轻量级锁、重量级锁) 随着锁竞争加剧,锁级别会逐渐升级。 (锁升级过程不可逆,即:锁级别只升不降)
todo markWord pol
todo 四个级别
锁类型:可重入锁(reentrant)/递归锁
可重入锁,也叫做递归锁,指的是同一线程 外层函数获得锁之后 ,内层递归函数仍然有获取该锁的代码,但不受影响。 在 JDK 中 ReentrantLock 和 synchronized 都是可重入锁。
public class Test implements Runnable {
ReentrantLock lock = new ReentrantLock();
public void get() {
lock.lock();
// ...
set();
lock.unlock();
}
public void set() {
lock.lock();
// ...
lock.unlock();
}
@Override
public void run() {
get();
}
}public class Test implements Runnable {
public synchronized void get() {
// ...
set();
}
public synchronized void set() {
// ...
}
@Override
public void run() {
get();
}
}public class SpinLock1 {
private AtomicReference<Thread> owner = new AtomicReference<>();
private int count = 0;
public void lock() {
Thread current = Thread.currentThread();
if (current == owner.get()) {
count++;
return;
}
while(!owner.compareAndSet(null, current)) {
// wait ... or else cpu busy
}
}
public void unlock() {
Thread current = Thread.currentThread();
if(current == owner.get()) {
if(count!=0) {
count--;
} else {
owner.compareAndSet(current, null);
}
}
}
}ReentrantLock 使用
todo timeout
todo trylock —— 防止获取锁失败后一直等待,可以自定义获取锁失败后的处理
todo lockInterruptibly —— 等待过程中中断
锁类型:公平锁、非公平锁
概念:
- 非公平 —— 优先将锁给统一线程的任务 💡 非公平锁能减少线程上下文切换的开销,理论上性能更好,所以锁默认都是非公平的
- 公平 —— 不同线程获取锁机会一样
e.g.
- synchronized 非公平
- ReentrantLock 可公平、可非公平
new ReentrantLock(true) ; // fair true/false 默认 false
Java任务编排接口
接口:线程结果(Callable、Future)
Future 是 JDK1.5 提供的接口,是用来以阻塞的方式获取线程异步执行完的结果。
- Callable 接口 —— Runnable 接口的替代接口,有返回值的一个单独任务
- Future 接口 —— 包含一些能获取 Callable 接口返回值并控制其状态的方法
获取线程返回值
package org.example.thread;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import java.util.List;
import java.util.concurrent.*;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
@Slf4j
public class FutureTest {
/**
* 直接调用
*/
@Test
void test01() {
FutureTask<Integer> future = new FutureTask<>((Callable<Integer>) () -> 5);
new Thread(future).start();
// ... 执行其他任务,不会阻塞
try {
log.info("taskId: {}", future.get());
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
}
final static ExecutorService executorService = Executors.newFixedThreadPool(2);
/**
* 线程池调用
*/
@Test
void test02() {
Future<Integer> future = executorService.submit((Callable<Integer>) () -> 42);
// ... 执行其他任务,不会阻塞
try {
log.info("taskId: {}", future.get());
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
}
/**
* 批量任务调用
*/
@Test
void test03() {
// 准备任务
List<Callable<Integer>> tasks = IntStream.rangeClosed(0,10)
.mapToObj(i -> (Callable<Integer>) () -> i)
.collect(Collectors.toList());
// 批量发布任务 (invoke 会阻塞,想要非阻塞使用 map.submit)
// List<Future<Integer>> results = executorService.invokeAll(tasks);
List<Future<Integer>> results = tasks.stream().map(executorService::submit).collect(Collectors.toList());
// ... 执行其他任务,不会阻塞
results.forEach(result -> {
try {
log.info("taskId: {}", result.get()); // Results are obtained in the order of task submission
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
});
}
}接口:CompletionService
批量异步工具。 功能: 异步提交任务,按完成顺序获取结果。
CompletionService 的底层原理: 阻塞队列、线程池
- 阻塞队列: CompletionService 使用阻塞队列保存已完成的任务。当一个任务完成时,它会被放入队列中。阻塞队列的选择通常是 LinkedBlockingQueue,它是一个先进先出的队列,确保按照任务完成的顺序排列。
- 线程池: CompletionService 需要与 Executor 框架一起使用。创建一个 ExecutorService,并将其传递给 CompletionService 的构造函数。这个线程池负责执行提交的任务。
package org.example.thread;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import java.util.concurrent.*;
import java.util.stream.IntStream;
@Slf4j
public class CompletionServiceTest {
final static ExecutorService pool = Executors.newFixedThreadPool(5);
/**
* 按照任务完成的先后顺序获取结果
*/
@Test
void test() {
CompletionService<Integer> completionService = new ExecutorCompletionService<>(pool);
IntStream.rangeClosed(0, 10).forEach(i -> completionService.submit((Callable<Integer>) () -> i));
try {
for (int i = 0; i < 10; i++) {
// 💡 如果队列为空,take() 方法会阻塞,而 poll() 方法会返回 null
Future<Integer> result = completionService.take(); // Blocking until a task is completed
log.info("taskId: {}", result.get()); // Results are obtained in the order of completion
}
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
}
}接口:CompletableFuture
JDK8 引入,解决 Future 和 CompletionService 都不擅长的 “异步任务编排组合” 问题,提供了“基于事件的异步编程范式”的支持。 在我们的日常优化中,最常用手段便是多线程并行执行。这时候就会涉及到 CompletableFuture 的使用。
// Future 异步计算的结果
// CompletionStage 以声明式的方式组合和链接异步操作,而不需要显式地处理回调函数
class CompletableFuture implements CompletionStage, Future特性:
- 解决 Future 的这些缺陷
- 函数式编程
- 异步任务编排组合(可以将多个异步任务串联起来,组成一个完整的链式调用)能力
原理: CompletableFuture 内部默认使用 ForkJoinPool 线程池(CPU密集型)执行任务。 CompletableFuture 以对任务完成的监听机制,实现非阻塞的特性。当任务完成时,它会遍历所有注册的回调函数,并在合适的线程中执行这些回调。通过这种机制,CompletableFuture 能够在任务完成后及时返回结果或触发后序处理逻辑,而不会阻塞主线程的执行。
接口:注册回调函数 —— thenApply/thenAccept/thenRun
通过 thenApply/thenAccept/thenRun 方法,注册回调函数,这些函数会在 CompletableFuture 完成时被异步调用。这样,处理任务的结果不必阻塞当前线程。
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "Hello");
future.thenApply(result -> {
// Non-blocking callback to process the result
System.out.println("Received result: " + result);
return result.toUpperCase();
});
// Continue with other non-blocking operations接口:任务的完成 —— 通过 thenCombine/thenAcceptBoth/runAfterBoth/applyToEither/acceptEither 等方法,将多个 CompletableFuture 的结果组合在一起,而不必阻塞等待每个任务的完成。
CompletableFuture<String> firstTask = CompletableFuture.supplyAsync(() -> {
// Simulate some computation
return "First Task";
});
CompletableFuture<String> secondTask = CompletableFuture.supplyAsync(() -> {
// Simulate some computation
return "Second Task";
});
CompletableFuture<String> thirdTask = CompletableFuture.supplyAsync(() -> {
// Simulate some computation
return "Third Task";
});
// 使用thenCompose确保任务按照顺序完成
CompletableFuture<String> result = firstTask.thenCompose(result1 ->
secondTask.thenCompose(result2 ->
thirdTask.thenApply(result3 -> result1 + " -> " + result2 + " -> " + result3)
)
);
// 异步获取结果
result.thenAcceptAsync(System.out::println);
// 阻塞等待所有任务完成
result.join();接口:异常处理
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
throw new RuntimeException();
})
.exceptionally(ex -> "errorFirstTask") // 处理异常并返回新结果
.thenApply(firstTask -> firstTask + "secondTask")
.thenApply(secondTask -> secondTask + "thirdTask")
.thenApply(thirdTask -> thirdTask + "lastTask")handle(BiFunction fn)CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "resultA")
.thenApply(firstTask -> firstTask + "secondTask")
.thenApply(secondTask -> {throw new RuntimeException();})
.handle(new BiFunction<Object, Throwable, Object>() { // 定义异常处理
@Override
public Object apply(Object re, Throwable throwable) {
if (throwable != null) {
return "errorThirdTask ";
}
return re;
}
})
.thenApply(thirdTask -> thirdTask + "lastTask");问题:区别 Future、CompletionService、CompletableFuture
https://blog.csdn.net/weixin_44153131/article/details/135389315
- Future —— JDK1.5 提供,解决线程执行结果收集问题。
- CompletionService —— 批量异步工具。异步提交任务,希望按完成顺序获取结果。
- CompletableFuture —— JDK8 引入,解决 Future 和 CompletionService 都不擅长的 “异步任务编排组合” 问题。
例子
详情
package org.example.thread;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import java.util.concurrent.CompletableFuture;
import java.util.function.BiFunction;
@Slf4j
public class CompletableFutureTest {
/**
* 启动异步任务
*/
@Test
void test_supplyAsync() {
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "Hello");
future.thenApply(result -> {
// Non-blocking callback to process the result
System.out.println("Received result: " + result);
return result.toUpperCase();
});
// Continue with other non-blocking operations
log.info("----");
future.join();
log.info("----");
}
/**
* 多任务编排
*/
@Test
void test_thenCompose() {
CompletableFuture<String> firstTask = CompletableFuture.supplyAsync(() -> {
// Simulate some computation
return "First Task";
});
CompletableFuture<String> secondTask = CompletableFuture.supplyAsync(() -> {
// Simulate some computation
return "Second Task";
});
CompletableFuture<String> thirdTask = CompletableFuture.supplyAsync(() -> {
// Simulate some computation
return "Third Task";
});
// 使用thenCompose确保任务按照顺序完成
CompletableFuture<String> result = firstTask.thenCompose(result1 ->
secondTask.thenCompose(result2 ->
thirdTask.thenApply(result3 -> result1 + " -> " + result2 + " -> " + result3)
)
);
// 异步获取结果
result.thenAcceptAsync(log::info);
// 阻塞等待所有任务完成
log.info("---");
result.join();
log.info("---");
}
/**
* 异常处理
*/
@Test
void test_exceptionally() {
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
throw new RuntimeException();
})
.exceptionally(ex -> "errorFirstTask")
.thenApply(firstTask -> firstTask + "secondTask")
.thenApply(secondTask -> secondTask + "thirdTask")
.thenApply(thirdTask -> thirdTask + "lastTask");
future.join();
}
/**
* 异常处理
*/
@Test
void test_handle() {
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "resultA")
.thenApply(firstTask -> firstTask + "secondTask")
.thenApply(secondTask -> {
throw new RuntimeException();
})
.handle(new BiFunction<Object, Throwable, Object>() {
@Override
public Object apply(Object re, Throwable throwable) {
if (throwable != null) {
return "errorThirdTask ";
}
return re;
}
})
.thenApply(thirdTask -> thirdTask + "lastTask");
future.join();
}
}扩展:超时处理(timeout)
参考:
- https://segmentfault.com/a/1190000045099797 —— Java CompletableFuture 异步超时实现探索
- https://juejin.cn/post/7411345808527147062/https://www.cnblogs.com/HuaTalkHub/p/18697082 —— 【异步编程实战】如何实现超时功能(以CompletableFuture为例)
JDK9+
JDK自身支持。略
public CompletableFuture<T> orTimeout(long timeout, TimeUnit unit) {
if (unit == null)
throw new NullPointerException();
if (result == null)
whenComplete(new Canceller(Delayer.delay(new Timeout(this), timeout, unit)));
return this;
}JDK8
JDK 8 中 CompletableFuture 没有上述方法,但我们可以实现一个:
CompletableFutureExpandUtils.orTimeout(异步任务, 超时时间, 时间单位);package com.jd.jr.market.reduction.util;
import com.jdpay.market.common.exception.UncheckedException;
import java.util.concurrent.*;
import java.util.function.BiConsumer;
/**
* CompletableFuture 扩展工具
*
* @author zhangtianci7
*/
public class CompletableFutureExpandUtils {
/**
* 如果在给定超时之前未完成,则异常完成此 CompletableFuture 并抛出 {@link TimeoutException} 。
*
* @param timeout 在出现 TimeoutException 异常完成之前等待多长时间,以 {@code unit} 为单位
* @param unit 一个 {@link TimeUnit},结合 {@code timeout} 参数,表示给定粒度单位的持续时间
* @return 入参的 CompletableFuture
*/
public static <T> CompletableFuture<T> orTimeout(CompletableFuture<T> future, long timeout, TimeUnit unit) {
if (null == unit) {
throw new UncheckedException("时间的给定粒度不能为空");
}
if (null == future) {
throw new UncheckedException("异步任务不能为空");
}
if (future.isDone()) {
return future;
}
return future.whenComplete(new Canceller(Delayer.delay(new Timeout(future), timeout, unit)));
}
/**
* 超时时异常完成的操作
*/
static final class Timeout implements Runnable {
final CompletableFuture<?> future;
Timeout(CompletableFuture<?> future) {
this.future = future;
}
public void run() {
if (null != future && !future.isDone()) {
future.completeExceptionally(new TimeoutException());
}
}
}
/**
* 取消不需要的超时的操作
*/
static final class Canceller implements BiConsumer<Object, Throwable> {
final Future<?> future;
Canceller(Future<?> future) {
this.future = future;
}
public void accept(Object ignore, Throwable ex) {
if (null == ex && null != future && !future.isDone()) {
future.cancel(false);
}
}
}
/**
* 单例延迟调度器,仅用于启动和取消任务,一个线程就足够
*/
static final class Delayer {
static ScheduledFuture<?> delay(Runnable command, long delay, TimeUnit unit) {
return delayer.schedule(command, delay, unit);
}
static final class DaemonThreadFactory implements ThreadFactory {
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setDaemon(true);
t.setName("CompletableFutureExpandUtilsDelayScheduler");
return t;
}
}
static final ScheduledThreadPoolExecutor delayer;
static {
delayer = new ScheduledThreadPoolExecutor(1, new DaemonThreadFactory());
delayer.setRemoveOnCancelPolicy(true);
}
}
}协程/虚拟线程
Java 19 引入虚拟线程概念,Java 21 落地虚拟线程。 Java 中的虚拟线程就是通过 steal 机制(基于 Fork/Join 框架)实现一个真实线程同时调度多个虚拟线程任务,这避免使用多个真实线程来调度多个协同的任务,从而避免线程间上下文切换的带来的系统开销。
适用场景:
- 虚拟线程适用于阻塞式任务,在阻塞期间,可以将CPU资源让渡给其他任务
- 虚拟线程不适用CPU密集计算或非阻塞任务,虚拟线程并不会运行的更快,而是增加了规模
- 像Tomcat、Jetty、Netty、SpringBoot等都已经支持虚拟线程
Demo: 代码: https://github.com/LawssssCat/blog/tree/master/code/demo-java-thread/
接口:Fork/Join 框架
todo pool 管理细节、pool 源码
参考:
- 使用 https://www.bilibili.com/video/BV1zb4y1J77G/
- todo 源码 https://www.bilibili.com/video/BV1C44y1W7n6/
- todo JDK19 虚拟线程基于 ForkJoin 的实现 https://www.bilibili.com/video/BV1Fd4y1w7MV?p=6
JDK 1.7 引入
Fork/Join 框架定义了一种特殊的执行器,采用分治方法进行求解问题:将一个大任务分解成一系列子任务(fork);当子任务执行完成后,将各自执行结果进行合并(join)成为一个大结果。
相关信息
Fork/Join 框架利用线程池(ForkJoinPool)调度任务。
关于该线程池,有如下概念:
- 多队列 —— 为了提高效率、减少线程竞争,Fork/Join 框架把这多个平行的任务放到不同的队列中去,这样 ForkJoinPool 线程池里面有多个任务队列(一般线程池只有一个任务队列)。
- 任务窃取(
WorkStealing) —— 线程池线程执行完自己任务队列中的任务后,会 “帮” 其他线程执行它们任务队列中的任务。 ref:newWorkStealingPool - 内部任务/外部任务 —— 在
ForkJoinWorkerThread线程中 Fork 出的任务属于 “内部任务”,这些任务被 ForkJoinPool 线程池内部优化调度;在线程外部通过 submit/execute/invoke 等方法提交给线程池的任务属于 “外部任务”,这些任务遵循一般线程池调度规则。- (内部)Fork —— 分治特性
- (外部)invoke【同步】 —— 方法调用后一直阻塞,直到任务执行完成才返回执行结果
- (外部)submit【异步】 —— 方法调用后马上返回 Future 类,通过该类的
get()方法来获取结果 - (外部)execute【异步】 —— 方法调用后马上返回,没有返回结果
接口/核心组件:
- ForkJoinPool(线程池) —— 该类实现了要用与运行任务的执行器
- 负责接收外部任务的提交
- 负责工作线程的创建和管理
- (特性)负责接收 Fork 出来的子任务的提交
- (特性)负责任务队列数组
workQueue[]的初始化和管理
- ForkJoinTask(要执行的任务) —— 在 ForkJoinPool 中执行的任务 JUC 设计如下子类:
RecursiveAction—— 没有返回结果的 ForkJoin 任务RecursiveTask—— 有返回结果的 ForkJoin 任务CountedCompleter—— 用于操作完成后需要触发其他操作的 ForkJoin 任务
- ForkJoinWorkerThread(执行线程) —— 在 ForkJoinPool 中执行任务的线程。每个 ForkJoinWorkerThread 都有一个自己的任务队列
- WorkQueue(任务队列)
使用了 ForkJoinPool 的 JDK 类:
Stream.parallelStream()CompletableFuture
demo:
package org.example.thread;
import com.google.common.base.Stopwatch;
import lombok.AllArgsConstructor;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import java.util.concurrent.*;
import java.util.function.Supplier;
import java.util.stream.LongStream;
@Slf4j
public class ForkJoinPoolTest {
@SneakyThrows
@Test
void teste() {
long start = 1L;
long end = 10000000000L;
// ForkJoinPool forkJoinPool = new ForkJoinPool(3); // 最大线程数
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool(); // 一般用公共的线程池即可
Future<Long> invoke = time("fork", () -> {
return forkJoinPool.invoke(new ForKJoinCalculate(start, end)); // invoke 同步等待结果
});
Future<Long> expect = time("common", () -> {
return LongStream.rangeClosed(start, end).sum();
});
Assertions.assertEquals(expect.get(), invoke.get());
}
private Future<Long> time(String key, Supplier<Long> func) {
return CompletableFuture.supplyAsync(() -> {
Stopwatch stopwatch = Stopwatch.createStarted();
long result = func.get();
stopwatch.stop();
log.info("{}: {}", key, stopwatch.toString());
return result;
});
}
/**
* 计算 ∑(n,m) 的结果
*/
@AllArgsConstructor
static class ForKJoinCalculate extends RecursiveTask<Long> {
private long start;
private long end;
/**
* 计算量少于该值,才开始计算结果;否则,Fork 出新任务,进行分治计算
*/
private static final long THRESHOLD = 10000L;
@Override
protected Long compute() {
if (end - start <= THRESHOLD) {
// log.debug("calc: {} -> {}", start, end);
long sum = 0l;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
// 分治
long old = end;
end = (start + end) / 2;
// ForkJoinTask<Long> left = new ForKJoinCalculate(start, end).fork();
ForkJoinTask<Long> right = new ForKJoinCalculate(end + 1, old).fork();
// return left.join() + right.join(); // 方法一:中(不必要的创建对象)
return compute() + right.join(); // 方法二:更快
}
}
}
}线程池(ThreadPool)
Java 里的线程池顶级接口是 java.util.concurrent.Executor 一个执行线程的工具和 java.util.concurrent.ExecutorService 一个线程管理服务。
配置参考:
- todo https://www.bilibili.com/video/BV1xE421M78a/
- todo https://www.bilibili.com/video/BV1HC411n7XL/
ExecutorService threadPool = new ThreadPoolExecutor(
10, // 💡 corePoolSize 核心线程数量 —— 创建,不回收
20, // 💡 maximumPoolSize 最大线程数量 —— 创建,回收
0L, // 💡 keepAliveTime 非核心线程存活时间
TimeUnit.SECONDS,
// 💡 workQueue 工作队列/阻塞队列 —— 超过核心线程数量后排队,队列满后才创建非核心线程处理任务
// e.g.
new ArrayBlockingQueue<Runnable>(3), // 基于数组的有界队列,先入先出(FIFO)原则排序
// new LinkedBlockingQueue // 基于链表的有界阻塞队列(不设置大小时,默认为 Integer.MAX_VALUE),先入先出(FIFO)原则排序
Executors.defaultThreadFactory(), // 💡 threadFactory 线程工厂 —— 可以用来绑定线程的异常处理器
// 💡 handler 拒绝策略 —— 阻塞队列满了、最大线程数也满了,则有拒绝策略处理
// e.g.
// new ThreadPoolExecutor.AbortPolicy() // 丢弃任务并抛出 RejectedExecutionException 异常 ❗可能造成调用者线程终止
new ThreadPoolExecutor.DiscardPolicy() // 丢弃任务不抛出异常
// new ThreadPoolExecutor.DiscardOldestPolicy() // 丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
// new ThreadPoolExecutor.CallerRunsPolicy() // 由调用线程处理该任务,e.g. 由 main 线程调用 runnable.run 方法
);
try {
for (int i=1; i<=10; i++) {
// 💡无返回值使用 execute;有返回值使用 submit
threadPool.execute(() -> {
// ...
});
}
} finally {
// threadPool.shutdownNow(); // (中断所有线程,)立即关闭线程池
threadPool.shutdown(); // (中断所有线程,)等待线程池中所有任务(正在执行的任务,队列中的任务)执行完毕后,关闭线程池
threadPool.awaitTermination(Long.MAX_VALUE, TimeUnit.SECONDS); // 等待线程池关闭,即线程池中所有线程执行完毕
threadPool.isTerminated(); // 判断线程正真结束。true = 线程池中的所有线程执行完毕
}线程池模型
线程池排队逻辑:
- 核心线程空闲 —— 核心线程处理
- 核心线程满了 —— 排队
- 核心线程满了,队列满了 —— 非核心线程处理
- 核心线程满了,队列满了,非核心线程满了 —— 拒绝策略
todo 整理图片,参考: https://www.bilibili.com/video/BV1J6421w7Jb
概念:非核心线程淘汰机制
参考: https://www.bilibili.com/video/BV177421Z7as?p=29
todo 理解 ThreadPoolExecutor.getTask 逻辑
- time、timeout 作用
- cas 竞争淘汰
概念:拒绝策略
当核心线程(corePoolSize)、任务队列(workQueue)、最大线程数(maximumPoolSize)都满了,就要执行 “拒绝策略”。
JDK 内置 4 种拒绝策略:
- AbortPolicy (默认) —— 丢弃任务,并抛出 RejectedExecutionException 异常 for 让程序员知道
- CallerRunsPolicy —— 丢弃任务,不抛出异常 for 无关紧要的业务
- DiscardOldestPolicy —— 丢弃任务队列最前的任务,将新任务放入队列末尾 for 重试业务
- DiscardPolicy —— 任务调度线程来执行当前任务 for 让所有任务都能得到执行,而使用多线程只作为增加吞吐量的手段 so 适合大量计算类型的业务
自定义拒绝策略:通过实现 RejectExecutionHandler 接口实现自定义拒绝策略。
class MyRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
try {
executor.getQueue().offer(r, 60, TimeUnit.SECONDS); // 超时等待
} catch (InterruptedExecution e) {
e.printStackTrace();
}
}
}开源项目自定义拒绝策略:
- dubbo(
org.apache.dubbo.common.threadpool.support.AbortPolicyWithReport) —— 当 dubbo 的工作线程触发了线程拒绝策略后,为了让使用者清楚触发线程拒绝策略的原因,拒绝策略做了三件事:- 输出告警日志 —— 内容包括:线程池的详细设置参数、线程池当前状态、拒绝的任务的详细信息
- 输出当前线程堆栈详情,将发生拒绝策略时的现场情况 dump 线程上下文信息到一个文件中
- 发送事件 onEvent
- 抛出拒绝执行异常,使本次任务失败(使用 JDK 默认拒绝策略的异常)
问题:区别 excute 和 submit 方法
| 区别 | execute | submit |
|---|---|---|
| 返回结果 | 无返回 | Future |
| 异常处理 | 线程中抛出 | Future.get 时抛出 |
| 方法重载 | 只接收 Runnable | 能接收 Runnable 和 Callable |
接口:扩展方法
线程池里面提供了几个空方法(钩子方法):
- beforeExecute
- afterExecute
- terminated
通过这些钩子方法可以实现如线程池状态统计、日志输出、告警通知等功能。
todo https://www.bilibili.com/video/BV1Bw4m1Z7eg?p=113
接口:异常处理
在 Java 中,线程池中的工作线程如果出现异常:
默认会把异常往外抛,但是抛出时机有区别
- 如果是 execute (无返回值)执行的任务,异常马上会在子线程抛出
- 如果是 submit (有返回值)执行的 FutureTask 执行的任务,异常会在
future.get时被捕获到
同时这个工作线程会因为异常销毁
线程池调用线程 run 方法时,会在外面包裹
try-catch-finally关键字,处理线程销毁工作try { task.run(); } catch (RuntimeException x) { thrown = x; throw x; } catch (Error x) { thrown = x; throw x; } catch (Throwable x) { thrown = x; throw new Error(x); } finally { afterExecute(task, thrown); }线程池销毁线程会通过 processWorkerExit 方法,将该异常线程从线程池的 workers 中移除
所以,为了避免异常导致的异常情况,我们需要手动处理对应的异常。 下面整理几种异常处理手段:
在传递的任务中处理异常(推荐)
Runnable task = () -> { try { // 执行任务... } catch (Exception e) { // 处理异常... } }; executor.submit(task);使用 Future 获取异常结果
Future<Integer> future = executor.submit(() -> { // 执行任务... return result; }); try { Integer result = future.get(); } catch (ExecutionException e) { Throwable cause = e.getCause(); // 获取实际的异常 // 处理异常... }自定义 ThreadFactory 指定线程池异常处理方式
ThreadFactory factory = runnable -> { Thread thread = new Thread(runnable); thread.setUncaughtExceptionHandler((t, e) -> { // 该方法在线程由于未捕获异常而即将终止的时候被调用 // 处理异常... }); return thread; }; ExecutorService executor = Executors.netFixedThreadPool(10, factory);注意
可能导致 UncaughtExceptionHandler 失效的情况:
如果异常由其他线程抛出(,一般是该线程下又用了其他线程,在其他线程中抛出异常),则不会被当前配置的 Handler 捕获并处理
如果 runnable 由线程池的 submit 方法执行(返回 Future 类),则不会被当前配置的 Handler 捕获并处理,因为该 Handler 只针对线程池的 execute 方法捕获异常
❗ 这种失效情况非常常见,如定时任务(
ScheduledExecutorService)的 schedule 底层调用 submit 方法,如果没意识且不针对性的调试,大概率踩坑详情
package org.example.thread; import lombok.extern.slf4j.Slf4j; import org.junit.jupiter.api.Test; import java.text.MessageFormat; import java.util.Date; import java.util.concurrent.*; import java.util.function.Function; /** * 模拟 schedule 捕获线程异常失效的情况 */ @Slf4j public class ScheduleExecutorServiceCaughtExceptionFailTest { /** * 捕获异常失效:异常日志 “exception in ...” 没有打印 */ @Test void testSchedule_FailCaughtException_01() { newAndCaughtExceptionAndSchedule(threadFactory -> { return new ScheduledThreadPoolExecutor(1, threadFactory); }); } /** * 捕获异常情况: 异常日志 “exception in ...” 没有打印 */ @Test void testSchedule_FailCaughtException_02() { newAndCaughtExceptionAndSchedule(threadFactory -> { return Executors.newSingleThreadScheduledExecutor(threadFactory); }); } private static void newAndCaughtExceptionAndSchedule(Function<ThreadFactory, ScheduledExecutorService> func) { Thread.UncaughtExceptionHandler uncaughtExceptionHandler = new Thread.UncaughtExceptionHandler() { @Override public void uncaughtException(Thread t, Throwable e) { log.warn(MessageFormat.format("exception in {0}", t.getName()), e); // 💡不走到这行 } }; ThreadFactory factory = new ThreadFactory() { @Override public Thread newThread(Runnable r) { log.debug("new thread!"); Thread thread = new Thread(r); thread.setUncaughtExceptionHandler(uncaughtExceptionHandler); // 💡配置有效,但功能没有被触发,应为该功能只有在线程池 execute 方法异常时才触发 return thread; } }; ScheduledExecutorService executorService = func.apply(factory); // 💡schedule 调用线程池 submit 方法,而非线程池 execute 方法 ScheduledFuture<?> scheduledFuture = executorService.scheduleWithFixedDelay(new Runnable() { @Override public void run() { log.info("---- {}", new Date()); try { int a = 1 / 0; } catch (RuntimeException e) { log.warn("throw: {}", e.getMessage()); throw e; } } }, 0, 1, TimeUnit.SECONDS); try { Thread.sleep(10000); } catch (InterruptedException e) { throw new RuntimeException(e); } } }- 尝试使用 Spring 的 ThreadPoolTaskExecutor 和 CallableDecorator 类修饰线程池解决。参考:https://www.coder.work/article/1816127
重写
ThreadPoolExecutor.afterExcute方法,处理传递的异常引用
问题:ThreadLocal在线程池中内存泄漏问题
如果在线程池中使用 ThreadLocal 可能会造成内存泄漏。
可能造成内存泄漏的推论:
- 线程对象是通过强引入指向 ThreadLocalMap 的
- ThreadLocalMap 也是强引用指向内部的 Entry
- 内部的 Entry key 和 value 值分别是 “
Runnable中的new ThreadLocalThreadLocal#xxxx” 和 “Runnable.run存入的值” - 当
Runnable.run结束后,ThreadLocal#xxxx依然被 Entry 强引用,但以无其他方式获取它 - 因为线程池该线程可能长时间存在,从而导致 Entry 这块内存无法被 gc 回收,导致内存泄漏
解决方法:
在线程池中,使用了 ThreadLocal 对象后,手动调用 ThreadLocal 的 remove 方法,手动清除 Entry 对象。
线程池工厂接口(Executor API)
接口:Executors
线程池有很多配置,为了简化配置,官方推荐使用 java.util.concurrent.Exectors 中的静态工厂类来生成一些常用的线程池。
- newFixedThreadPool —— 固定容量线程池
- newCachedThreadPool —— 可缓存线程池。当需求较小,回收空闲线程;当需求过量,增加线程数(无上限)
- newWorkStealingPool —— (JDK8 新引入的)具有抢占式操作(work-stealing 算法,基于 ForkJoinPool 的扩展)的线程池。如果一个线程完成了工作并且无事可做,则可以从另一线程的队列中 “窃取” 工作。这在任务较小时非常有用,该任务可以由任何可用线程主动拾取,从而减少了线程空闲时间。
- newSingleThreadPoolExecutor —— 单线程 Executor
- newScheduledThreadPool —— 固定容量线程池,且可延时启动任务和定时任务启动
接口:ExecutorService
Executors 工厂类统一返回该接口,区别是实现类的不同功能。
ScheduledExecutorService
参考: https://blog.csdn.net/Mrxiao_bo/article/details/136435896
ScheduledExecutorService 是 Java 并发包提供的接口,用于支持任务的调度和执行。 相较于传统的 Timer 类,ScheduledExecutorService 具有更强大的性能、更灵活的定时任务调度策略。
常见使用问题
问题:循环中使用多线程
Arrays.asList().stream().parallel()....
IntStream.of().parallel()....
LongStream.of().parallel()....问题:多线程操作集合(CopyOnWrite)
多线程同时操作同一个集合会抛出异常,因为异常迭代器有 “Fail-Fast(快速失败机制)”:当迭代器发现(其他代码)增删后,便抛出异常 java.util.ConcurrentModificationException —— 保证迭代器的独立性和隔离性
List<String> list = new ArrayList();
list.add("hello");
Iterator iterator = list.iterator();
list.add("world"); // 其他代码增删
iterator.next(); // 抛出异常处理这种情况,可以用 “写入时复制机制(CopyOnWrite,COW)” —— 希望迭代期间,能增删和高性能
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
static final class COWIterator<E> implements ListIterator<E> {
public E next() {
if (! hasNext())
throw new NoSuchElementException();
return (E) snapshot[cursor++];
}
}- 增删时,复制新数组,将引用挨个复制到新数组后,在新数组上操作 —— ❗ 所以写的性能,非常差!非常差!非常差!
- 遍历时,正常遍历
- 适用于读多,写少的情况
问题:ConcurrentHashMap 实现原理
ConcurrentHashMap 数据结构如下:
Segment[] (💡 Segment 继承 ReentrantLock 实现分段线程安全)
0 - HashEntry[] - HashEntry1,HashEntry2,... (单向链表)
1 - HashEntry[]
2 - HashEntry[]
3 - HashEntry[]
4 - HashEntry[]
5 - HashEntry[]
6 - HashEntry[]
7 - HashEntry[]
8 - HashEntry[]
...
16 (默认 16 个 segment 锁,相当于最大支持 16 个并发 put 操作)提示
与 HashMap 一样,在 JDK 1.8 后,对碰撞增加了 “红黑树” 的处理。
提示
concurrencyLevel 配置与 segment 数量的关系: https://www.infoq.cn/article/ConcurrentHashMap
- segments 数组的长度 ssize 通过 concurrencyLevel 计算得出
- 必须保证 segments 数组的长度是 2 的 N 次方(power-of-two size)
- e.g. 假如 concurrencyLevel 等于 14,15 或 16,ssize 都会等于 16,即容器里锁的个数也是 16
问题:多线程间,事务失效(❗ 解决方案有问题)
todo 移到 spring 并在这里提示
参考:
- https://www.bilibili.com/video/BV1Lf421Q7BY/
注意
多线程间共享一个事务,本身违背隔离性,应优先解决设计问题,而非下面所述代码问题。
问题:每个线程中的数据库连接(CurrentConnection)是不同的、独立的
@Transactional
public void transactionAsyncFail() {
new Thread(() -> {
addUser(1);
}).start();
addUser(3);
throw new RuntimeException("手动回滚");
}解决:
public void transactionAsyncSuccess() {
int size = 10;
CyclicBarrier barrier = new CyclicBarrier(size);
AtomicReference<Boolean> roolback = new AtomicReference<>(false);
for (int i=0; i<size; i++) {
int currentNum = i;
new Thread(() -> {
// 手动开启事务
TransactionStatus transaction = transactionManager.getTransaction(transactionDefinition);
try {
// insert 操作,如果插入数据 < 1 则异常
if (addUser(currentNum) < 1) {
log..info("手动异常");
throw new RuntimeException("插入数据失败");
}
} catch (Exception e) {
// 如果当前线程执行异常,则设置回滚标志
rollback.set(true);
}
// 等待所有线程的事务结束
try {
barrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
throw new RuntimeException(e);
}
// 如果标志需要回滚,则回滚
log.info("我执行了{}", currentNum);
if (rollback.get()) {
transactionManager.rollback(transaction);
log.info("rollback for {}", currentNum);
return;
}
transactionManager.commit(transaction);
}).start();
}
try {
Thread.sleep(1000);
} catch(InterruptedException e) {
throw new RuntimeException(e);
}
log.info("hello");
}坑:
- 多线程长时间占用,线程池占满
- 死锁
- 干扰实际的数据库实务间的隔离性
- 可以用 “分布式实务” 或 “最终一致” 解决
问题:动态线程池 with Nacos
todo https://www.bilibili.com/video/BV1Bw4m1Z7eg?p=108
所谓 “动态线程池” 指在不重启服务的情况下,改变线程池核心线程数量、最大线程数量、队列容量等。
动态修改配置
环境:(基于 Spring Cloud Alibaba 版本说明)
- Spring Boot 2.6.3
- Spring Cloud 2021.0.1
- Spring Cloud Alibaba 2021.0.1.0
- Nacos 1.4.2
./startup.sh -m standalone # 单机启动,否则以集群方式启动需要额外配置,麻烦
# 日志: ${NACOS_HOME}/logs/start.out
# 访问: http://ip:8848/nacos 默认用户/密码: nacos/nacosserver.port=7070
spring.application.name=dynamic-thread-pool
spring.cloud.nacos.config.server-addr=8.142.44.107:8848
spring.cloud.nacos.config.name=dynamic-thread-pool
spring.cloud.nacos.username=nacos
spring.cloud.nacos.password=nacos/**
* 添加下面配置,会生成对自定义配置文件的提示
* <dependency>
* <groupId>org.springframework.boot</groupId>
* <artifactId>spring-boot-configuration-processor</artifactId>
* <optional>true</optional>
* </dependency>
*
* 默认配置
* thread.pool.core-pool-size=16
* thread.pool.maximum-pool-size=16
* thread.pool.work-queue-size=1024
*/
@Data
@Component
@ConfigurationProperties(perfix = "thread.pool")
public class ThreadPoolProperties {
private int corePoolSize;
private int maximumPoolSize;
private long keepAliveTime;
private int workQueue;
}@Configuration
public class ThreadPoolConfig {
@Autowired
private ThreadPoolProperties threadPoolProperties;
@Bean
public ThreadPoolExecutor threadPoolExecutor() {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
threadPoolProperties.getCorePoolSize(),
threadPoolProperties.getMaximumPoolSize(),
threadPoolProperties.getKeepAliveTime(),
TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(threadPoolProperties.getWorkQueueSize()),
Executors.defaultThreadFactory(),
// Executors.privilegedThreadFactory(),
new ThreadPoolExecutor.DiscardPolicy()
)
}
}方法一: @RefreshScope —— 刷新 bean 配置
@RefreshScope
@Bean
public ThreadPoolExecutor threadPoolExecutor() { // ...方法二: 自己编写刷新代码
@Bean
public ThreadPoolExecutor threadPoolExecutor() {
ThreadPoolExecutor threadPoolExecutor = new DynamicThreadPoolExecutor( // DynamicThreadPoolExecutor 自定义类
// ...public class DynamicThreadPoolExecutor extends ThreadPoolExecutor {
// ... super method
}@Component
public class DynamicThreadPoolExecutorManager {
@Autowired
private ApplicationContext applicationContext;
public synchronized void refreshThreadPoolExecutor(Properties properties) { // 💡加锁,避免ABA
applicationContext.getBeansOfType(DynamicThreadPoolExecutor.class).forEach((beanName, executor) -> {
executor.setCorePoolSize(Integer.parseInt(properties.getProperty("thread.pool.core-pool-size")));
executor.setMaximumPoolSize(Integer.parseInt(properties.getProperty("thread.pool.maximum-pool-size")));
// 自定义队列 because of 队列无法通过线程池设置大小
if (executor.getQueue() instanceof ResizeLinkedBlockingQueue) {
((ResizeLinkedBlockingQueue) executor.getQueue()).updateCapacity(properties.getProperty("work-queue-size"));
}
});
}
}public class ResizeLinkedBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
// ...
void updateCapacity(int size) {
// ...
}
} @Bean
public ThreadPoolExecutor threadPoolExecutor() {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
threadPoolProperties.getCorePoolSize(),
threadPoolProperties.getMaximumPoolSize(),
threadPoolProperties.getKeepAliveTime(),
TimeUnit.SECONDS,
new ResizeLinkedBlockingQueue<Runnable>(threadPoolProperties.getWorkQueueSize()), // 💡注入自定义队列
Executors.defaultThreadFactory(),
// Executors.privilegedThreadFactory(),
new ThreadPoolExecutor.DiscardPolicy()
)
}@Component
public class NacosConfigListener implements ApplicationRunner {
@Atuowired
private NacosConfigManager nacosConfigManager;
@Autowired
private DynamicThreadPoolExecutorManager dynamicThreadPoolExecutorManager;
@Override
public void run(ApplicationArguments args) throws Execption {
// 开始监听 nacos 的配置更新
String dataId = nacosConfigManager.getNacosConfigProperties().getName();
String group = nacosConfigManager.getNacosConfigProperties().getGroup();
nacosConfigManager.getConfigService().addListener(dataId, group, new Listener() {
@Override
public Executor getExecutor() {
return null;
}
// 更新后的配置信息在此方法中接收
@Override
public void receiveConfigInfo(
String configInfo // 更新后的配置信息
) {
// 刷新我们的线程池配置类
Properties properties = new Properties();
try {
properties.load(new StringReader(configInfo));
} catch (IOException e) {
e.printStackTrace();
}
dynamicThreadPoolExecutorManager.refreshThreadPoolExecutor(properties);
}
})
}
}参考
- openjdk线程源码实现 —— https://www.bilibili.com/video/BV1Bw4m1Z7eg?p=11
待整理
特性:
todo Java 22 引入 Structured Task Scope 和 Subtask 处理结构化的异步行为 | 结合虚拟线程和结构化并发 | 虚拟线程使得阻塞不是问题,结构化并发让异步编程更直观。 | 有可能替代 CompletableFuture
模型:
todo 生产者/消费者模型
工具:
todo 多线程测试方式 https://github.com/awaitility/awaitility 【开源框架】
todo dynamic-tp —— 美团开源的动态线程池,支持通过 nacos 配置中心配置线程池,对线程池进行扩缩容。 【开源框架】
todo 多余线程的处理 —— 队列缩容处理
todo 分布式锁 —— 原理就是找 redis/mq 这些第三方存锁的状态,加锁时候去看一下,加了锁更新一下。 https://www.bilibili.com/video/BV1vM4m1k7qB/
todo AQS(AbstractQueuedSynchronizer,抽象队列同步器)框架 主要用来构建锁和同步器
- todo Java 面试题:AQS 条件等待和唤醒的实现原理 —— https://www.bilibili.com/video/BV1gN411J7Na/
- todo Java 面试题:AQS 实现原理之互斥模式 —— https://www.bilibili.com/video/BV1mF41117VQ/
- todo Java 面试题:AQS 共享模式在读写锁中的应用 —— https://www.bilibili.com/video/BV1Rh4y1z7Zn/
- todo JavaGuide | AQS 详解 —— https://javaguide.cn/java/concurrent/aqs.html
- todo 美团 | 从 ReentrantLock 的实现看 AQS 的原理及应用 —— https://tech.meituan.com/2019/12/05/aqs-theory-and-apply.html
- todo
AQS 是什么?AbstractQueuedSynchronizer 之 AQS 原理及源码深度分析 —— https://blog.csdn.net/A_art_xiang/article/details/133985680